

ਵੱਡੀ ਭਾਸ਼ਾ ਦੇ ਮਾਡਲ ਕੀ ਹਨ?
ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲ (LLMs) ਉੱਨਤ ਨਕਲੀ ਬੁੱਧੀ (AI) ਸਿਸਟਮ ਹਨ ਜੋ ਮਨੁੱਖੀ-ਵਰਗੇ ਟੈਕਸਟ ਨੂੰ ਪ੍ਰਕਿਰਿਆ ਕਰਨ, ਸਮਝਣ ਅਤੇ ਬਣਾਉਣ ਲਈ ਤਿਆਰ ਕੀਤੇ ਗਏ ਹਨ। ਉਹ ਡੂੰਘੀ ਸਿੱਖਣ ਦੀਆਂ ਤਕਨੀਕਾਂ 'ਤੇ ਆਧਾਰਿਤ ਹੁੰਦੇ ਹਨ ਅਤੇ ਵਿਸ਼ਾਲ ਡੇਟਾਸੈਟਾਂ 'ਤੇ ਸਿਖਲਾਈ ਪ੍ਰਾਪਤ ਹੁੰਦੇ ਹਨ, ਆਮ ਤੌਰ 'ਤੇ ਵੈੱਬਸਾਈਟਾਂ, ਕਿਤਾਬਾਂ ਅਤੇ ਲੇਖਾਂ ਵਰਗੇ ਵਿਭਿੰਨ ਸਰੋਤਾਂ ਤੋਂ ਅਰਬਾਂ ਸ਼ਬਦ ਹੁੰਦੇ ਹਨ। ਇਹ ਵਿਆਪਕ ਸਿਖਲਾਈ LLM ਨੂੰ ਭਾਸ਼ਾ, ਵਿਆਕਰਣ, ਸੰਦਰਭ, ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ ਆਮ ਗਿਆਨ ਦੇ ਕੁਝ ਪਹਿਲੂਆਂ ਦੀਆਂ ਬਾਰੀਕੀਆਂ ਨੂੰ ਸਮਝਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੀ ਹੈ।
ਕੁਝ ਪ੍ਰਸਿੱਧ ਐਲਐਲਐਮ, ਜਿਵੇਂ ਕਿ ਓਪਨਏਆਈ ਦੇ ਜੀਪੀਟੀ-3, ਇੱਕ ਟ੍ਰਾਂਸਫਾਰਮਰ ਨਾਮਕ ਇੱਕ ਕਿਸਮ ਦੇ ਨਿਊਰਲ ਨੈਟਵਰਕ ਨੂੰ ਨਿਯੁਕਤ ਕਰਦੇ ਹਨ, ਜੋ ਉਹਨਾਂ ਨੂੰ ਗੁੰਝਲਦਾਰ ਭਾਸ਼ਾ ਦੇ ਕੰਮਾਂ ਨੂੰ ਸ਼ਾਨਦਾਰ ਮੁਹਾਰਤ ਨਾਲ ਸੰਭਾਲਣ ਦੀ ਆਗਿਆ ਦਿੰਦਾ ਹੈ। ਇਹ ਮਾਡਲ ਬਹੁਤ ਸਾਰੇ ਕਾਰਜ ਕਰ ਸਕਦੇ ਹਨ, ਜਿਵੇਂ ਕਿ:
- ਪ੍ਰਸ਼ਨਾਂ ਦੇ ਜਵਾਬ
- ਪਾਠ ਦਾ ਸੰਖੇਪ
- ਭਾਸ਼ਾਵਾਂ ਦਾ ਅਨੁਵਾਦ ਕਰਨਾ
- ਸਮੱਗਰੀ ਤਿਆਰ ਕਰ ਰਿਹਾ ਹੈ
- ਇੱਥੋਂ ਤੱਕ ਕਿ ਉਪਭੋਗਤਾਵਾਂ ਨਾਲ ਇੰਟਰਐਕਟਿਵ ਗੱਲਬਾਤ ਵਿੱਚ ਵੀ ਸ਼ਾਮਲ ਹੋਣਾ
ਜਿਵੇਂ ਕਿ LLMs ਦਾ ਵਿਕਾਸ ਕਰਨਾ ਜਾਰੀ ਹੈ, ਉਹ ਗਾਹਕ ਸੇਵਾ ਅਤੇ ਸਮੱਗਰੀ ਨਿਰਮਾਣ ਤੋਂ ਲੈ ਕੇ ਸਿੱਖਿਆ ਅਤੇ ਖੋਜ ਤੱਕ, ਉਦਯੋਗਾਂ ਵਿੱਚ ਵੱਖ-ਵੱਖ ਐਪਲੀਕੇਸ਼ਨਾਂ ਨੂੰ ਵਧਾਉਣ ਅਤੇ ਸਵੈਚਲਿਤ ਕਰਨ ਦੀ ਬਹੁਤ ਸੰਭਾਵਨਾ ਰੱਖਦੇ ਹਨ। ਹਾਲਾਂਕਿ, ਉਹ ਨੈਤਿਕ ਅਤੇ ਸਮਾਜਕ ਚਿੰਤਾਵਾਂ ਵੀ ਉਠਾਉਂਦੇ ਹਨ, ਜਿਵੇਂ ਕਿ ਪੱਖਪਾਤੀ ਵਿਵਹਾਰ ਜਾਂ ਦੁਰਵਰਤੋਂ, ਜਿਨ੍ਹਾਂ ਨੂੰ ਤਕਨਾਲੋਜੀ ਦੇ ਵਿਕਾਸ ਵਜੋਂ ਸੰਬੋਧਿਤ ਕੀਤੇ ਜਾਣ ਦੀ ਲੋੜ ਹੈ।

ਵੱਡੇ ਭਾਸ਼ਾ ਦੇ ਮਾਡਲਾਂ ਦੀਆਂ ਪ੍ਰਸਿੱਧ ਉਦਾਹਰਨਾਂ
ਇੱਥੇ ਵੱਖ-ਵੱਖ ਉਦਯੋਗਾਂ ਦੇ ਵਰਟੀਕਲਾਂ ਵਿੱਚ ਵਿਆਪਕ ਤੌਰ 'ਤੇ ਵਰਤੇ ਜਾਂਦੇ LLM ਦੀਆਂ ਕੁਝ ਪ੍ਰਮੁੱਖ ਉਦਾਹਰਣਾਂ ਹਨ:
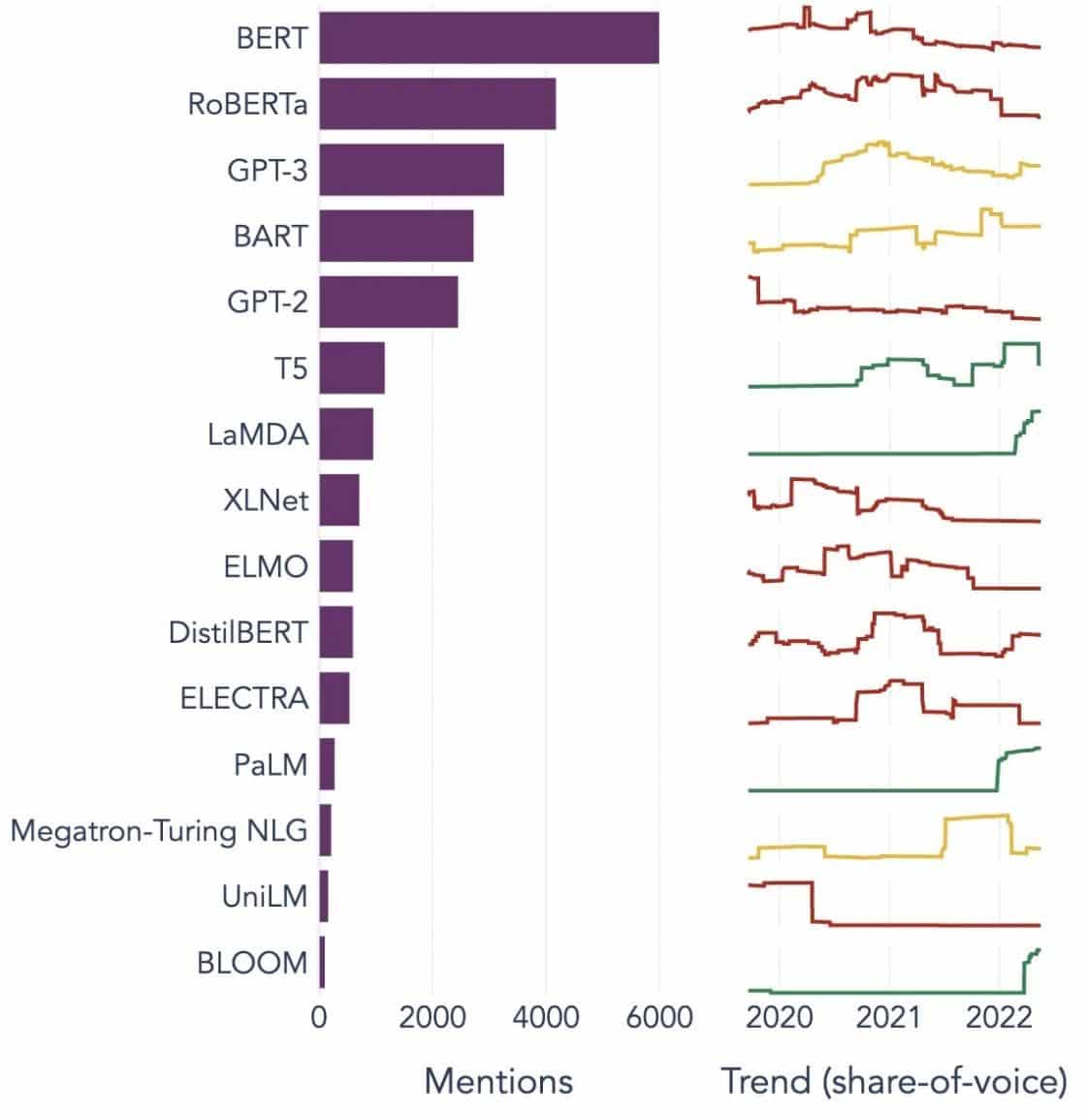
ਚਿੱਤਰ ਸਰੋਤ: ਡਾਟਾ ਸਾਇੰਸ ਵੱਲ
LLM ਮਾਡਲਾਂ ਨੂੰ ਕਿਵੇਂ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ?
ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲਾਂ (LLMs) ਨੂੰ ਸਿਖਲਾਈ ਦੇਣਾ ਕਾਫ਼ੀ ਇੱਕ ਕਾਰਨਾਮਾ ਹੈ ਜਿਸ ਵਿੱਚ ਕਈ ਮਹੱਤਵਪੂਰਨ ਕਦਮ ਸ਼ਾਮਲ ਹੁੰਦੇ ਹਨ। ਇੱਥੇ ਪ੍ਰਕਿਰਿਆ ਦਾ ਇੱਕ ਸਰਲ, ਕਦਮ-ਦਰ-ਕਦਮ ਰਨਡਾਉਨ ਹੈ:
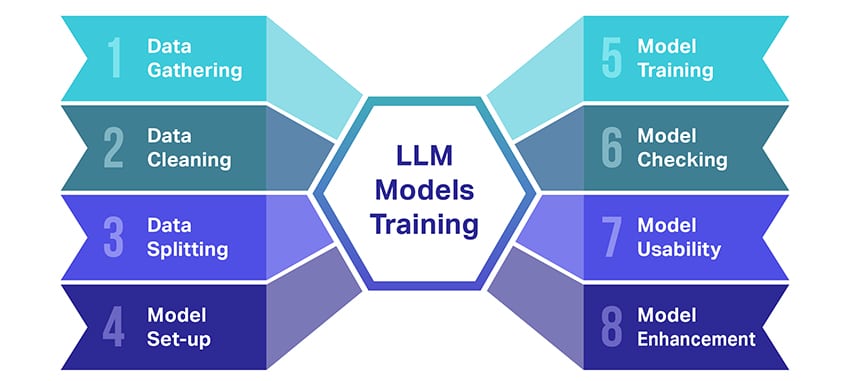
- ਟੈਕਸਟ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ: ਇੱਕ LLM ਦੀ ਸਿਖਲਾਈ ਬਹੁਤ ਸਾਰੇ ਟੈਕਸਟ ਡੇਟਾ ਦੇ ਸੰਗ੍ਰਹਿ ਨਾਲ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ। ਇਹ ਡੇਟਾ ਕਿਤਾਬਾਂ, ਵੈੱਬਸਾਈਟਾਂ, ਲੇਖਾਂ ਜਾਂ ਸੋਸ਼ਲ ਮੀਡੀਆ ਪਲੇਟਫਾਰਮਾਂ ਤੋਂ ਆ ਸਕਦਾ ਹੈ। ਉਦੇਸ਼ ਮਨੁੱਖੀ ਭਾਸ਼ਾ ਦੀ ਅਮੀਰ ਵਿਭਿੰਨਤਾ ਨੂੰ ਹਾਸਲ ਕਰਨਾ ਹੈ।
- ਡੇਟਾ ਨੂੰ ਸਾਫ਼ ਕਰਨਾ: ਕੱਚੇ ਟੈਕਸਟ ਡੇਟਾ ਨੂੰ ਫਿਰ ਪ੍ਰੀਪ੍ਰੋਸੈਸਿੰਗ ਨਾਮਕ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਜੋੜਿਆ ਜਾਂਦਾ ਹੈ। ਇਸ ਵਿੱਚ ਅਣਚਾਹੇ ਅੱਖਰਾਂ ਨੂੰ ਹਟਾਉਣਾ, ਟੈਕਸਟ ਨੂੰ ਟੋਕਨ ਕਹੇ ਜਾਣ ਵਾਲੇ ਛੋਟੇ ਹਿੱਸਿਆਂ ਵਿੱਚ ਵੰਡਣਾ, ਅਤੇ ਇਸ ਸਭ ਨੂੰ ਇੱਕ ਅਜਿਹੇ ਫਾਰਮੈਟ ਵਿੱਚ ਪ੍ਰਾਪਤ ਕਰਨਾ ਸ਼ਾਮਲ ਹੈ ਜਿਸ ਨਾਲ ਮਾਡਲ ਕੰਮ ਕਰ ਸਕਦਾ ਹੈ।
- ਡੇਟਾ ਨੂੰ ਵੰਡਣਾ: ਅੱਗੇ, ਸਾਫ਼ ਡੇਟਾ ਨੂੰ ਦੋ ਸੈੱਟਾਂ ਵਿੱਚ ਵੰਡਿਆ ਗਿਆ ਹੈ। ਇੱਕ ਸੈੱਟ, ਸਿਖਲਾਈ ਡੇਟਾ, ਮਾਡਲ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣ ਲਈ ਵਰਤਿਆ ਜਾਵੇਗਾ। ਦੂਜਾ ਸੈੱਟ, ਪ੍ਰਮਾਣਿਕਤਾ ਡੇਟਾ, ਮਾਡਲ ਦੀ ਕਾਰਗੁਜ਼ਾਰੀ ਦੀ ਜਾਂਚ ਕਰਨ ਲਈ ਬਾਅਦ ਵਿੱਚ ਵਰਤਿਆ ਜਾਵੇਗਾ।
- ਮਾਡਲ ਦੀ ਸਥਾਪਨਾ: ਐਲਐਲਐਮ ਦੀ ਬਣਤਰ, ਜਿਸਨੂੰ ਆਰਕੀਟੈਕਚਰ ਕਿਹਾ ਜਾਂਦਾ ਹੈ, ਨੂੰ ਫਿਰ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਇਸ ਵਿੱਚ ਨਿਊਰਲ ਨੈੱਟਵਰਕ ਦੀ ਕਿਸਮ ਦੀ ਚੋਣ ਕਰਨਾ ਅਤੇ ਵੱਖ-ਵੱਖ ਮਾਪਦੰਡਾਂ 'ਤੇ ਫੈਸਲਾ ਕਰਨਾ ਸ਼ਾਮਲ ਹੈ, ਜਿਵੇਂ ਕਿ ਨੈੱਟਵਰਕ ਦੇ ਅੰਦਰ ਲੇਅਰਾਂ ਦੀ ਗਿਣਤੀ ਅਤੇ ਛੁਪੀਆਂ ਇਕਾਈਆਂ।
- ਮਾਡਲ ਦੀ ਸਿਖਲਾਈ: ਅਸਲ ਸਿਖਲਾਈ ਹੁਣ ਸ਼ੁਰੂ ਹੁੰਦੀ ਹੈ. LLM ਮਾਡਲ ਸਿਖਲਾਈ ਡੇਟਾ ਨੂੰ ਦੇਖ ਕੇ, ਹੁਣ ਤੱਕ ਜੋ ਕੁਝ ਸਿੱਖਿਆ ਹੈ ਉਸ ਦੇ ਆਧਾਰ 'ਤੇ ਪੂਰਵ-ਅਨੁਮਾਨਾਂ ਬਣਾ ਕੇ, ਅਤੇ ਫਿਰ ਇਸਦੇ ਪੂਰਵ-ਅਨੁਮਾਨਾਂ ਅਤੇ ਅਸਲ ਡੇਟਾ ਵਿਚਕਾਰ ਅੰਤਰ ਨੂੰ ਘਟਾਉਣ ਲਈ ਇਸਦੇ ਅੰਦਰੂਨੀ ਮਾਪਦੰਡਾਂ ਨੂੰ ਅਨੁਕੂਲਿਤ ਕਰਕੇ ਸਿੱਖਦਾ ਹੈ।
- ਮਾਡਲ ਦੀ ਜਾਂਚ ਕੀਤੀ ਜਾ ਰਹੀ ਹੈ: LLM ਮਾਡਲ ਦੀ ਸਿਖਲਾਈ ਨੂੰ ਪ੍ਰਮਾਣਿਕਤਾ ਡੇਟਾ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਜਾਂਚਿਆ ਜਾਂਦਾ ਹੈ। ਇਹ ਇਹ ਦੇਖਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ ਕਿ ਮਾਡਲ ਕਿੰਨਾ ਵਧੀਆ ਪ੍ਰਦਰਸ਼ਨ ਕਰ ਰਿਹਾ ਹੈ ਅਤੇ ਬਿਹਤਰ ਪ੍ਰਦਰਸ਼ਨ ਲਈ ਮਾਡਲ ਦੀਆਂ ਸੈਟਿੰਗਾਂ ਨੂੰ ਟਵੀਕ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
- ਮਾਡਲ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ: ਸਿਖਲਾਈ ਅਤੇ ਮੁਲਾਂਕਣ ਤੋਂ ਬਾਅਦ, LLM ਮਾਡਲ ਵਰਤੋਂ ਲਈ ਤਿਆਰ ਹੈ। ਇਸਨੂੰ ਹੁਣ ਐਪਲੀਕੇਸ਼ਨਾਂ ਜਾਂ ਸਿਸਟਮਾਂ ਵਿੱਚ ਏਕੀਕ੍ਰਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ ਜਿੱਥੇ ਇਹ ਦਿੱਤੇ ਗਏ ਨਵੇਂ ਇਨਪੁਟਸ ਦੇ ਅਧਾਰ ਤੇ ਟੈਕਸਟ ਤਿਆਰ ਕਰੇਗਾ।
- ਮਾਡਲ ਵਿੱਚ ਸੁਧਾਰ: ਅੰਤ ਵਿੱਚ, ਇੱਥੇ ਹਮੇਸ਼ਾ ਸੁਧਾਰ ਲਈ ਜਗ੍ਹਾ ਹੁੰਦੀ ਹੈ। LLM ਮਾਡਲ ਨੂੰ ਸਮੇਂ ਦੇ ਨਾਲ ਹੋਰ ਸੁਧਾਰਿਆ ਜਾ ਸਕਦਾ ਹੈ, ਅਪਡੇਟ ਕੀਤੇ ਡੇਟਾ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਜਾਂ ਫੀਡਬੈਕ ਅਤੇ ਅਸਲ-ਸੰਸਾਰ ਵਰਤੋਂ ਦੇ ਅਧਾਰ 'ਤੇ ਸੈਟਿੰਗਾਂ ਨੂੰ ਵਿਵਸਥਿਤ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਯਾਦ ਰੱਖੋ, ਇਸ ਪ੍ਰਕਿਰਿਆ ਲਈ ਮਹੱਤਵਪੂਰਨ ਗਣਨਾਤਮਕ ਸਰੋਤਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਜਿਵੇਂ ਕਿ ਸ਼ਕਤੀਸ਼ਾਲੀ ਪ੍ਰੋਸੈਸਿੰਗ ਯੂਨਿਟ ਅਤੇ ਵੱਡੀ ਸਟੋਰੇਜ, ਨਾਲ ਹੀ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਵਿੱਚ ਵਿਸ਼ੇਸ਼ ਗਿਆਨ। ਇਸ ਲਈ ਇਹ ਆਮ ਤੌਰ 'ਤੇ ਸਮਰਪਿਤ ਖੋਜ ਸੰਸਥਾਵਾਂ ਜਾਂ ਲੋੜੀਂਦੇ ਬੁਨਿਆਦੀ ਢਾਂਚੇ ਅਤੇ ਮੁਹਾਰਤ ਤੱਕ ਪਹੁੰਚ ਵਾਲੀਆਂ ਕੰਪਨੀਆਂ ਦੁਆਰਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਕੀ LLM ਨਿਰੀਖਣ ਜਾਂ ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ?
ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲਾਂ ਨੂੰ ਆਮ ਤੌਰ 'ਤੇ ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ ਕਿਹਾ ਜਾਂਦਾ ਹੈ। ਸਧਾਰਨ ਸ਼ਬਦਾਂ ਵਿੱਚ, ਇਸਦਾ ਮਤਲਬ ਹੈ ਕਿ ਉਹ ਉਹਨਾਂ ਉਦਾਹਰਣਾਂ ਤੋਂ ਸਿੱਖਦੇ ਹਨ ਜੋ ਉਹਨਾਂ ਨੂੰ ਸਹੀ ਜਵਾਬ ਦਿਖਾਉਂਦੇ ਹਨ।
 ਕਲਪਨਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਇੱਕ ਬੱਚੇ ਨੂੰ ਤਸਵੀਰਾਂ ਦਿਖਾ ਕੇ ਸ਼ਬਦ ਸਿਖਾ ਰਹੇ ਹੋ। ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਇੱਕ ਬਿੱਲੀ ਦੀ ਤਸਵੀਰ ਦਿਖਾਉਂਦੇ ਹੋ ਅਤੇ "ਬਿੱਲੀ" ਕਹਿੰਦੇ ਹੋ ਅਤੇ ਉਹ ਉਸ ਤਸਵੀਰ ਨੂੰ ਸ਼ਬਦ ਨਾਲ ਜੋੜਨਾ ਸਿੱਖਦੇ ਹਨ। ਇਸ ਤਰ੍ਹਾਂ ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ ਕੰਮ ਕਰਦੀ ਹੈ। ਮਾਡਲ ਨੂੰ ਬਹੁਤ ਸਾਰੇ ਟੈਕਸਟ ("ਤਸਵੀਰਾਂ") ਅਤੇ ਸੰਬੰਧਿਤ ਆਉਟਪੁੱਟ ("ਸ਼ਬਦ") ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਇਹ ਉਹਨਾਂ ਨੂੰ ਮੇਲਣਾ ਸਿੱਖਦਾ ਹੈ।
ਕਲਪਨਾ ਕਰੋ ਕਿ ਤੁਸੀਂ ਇੱਕ ਬੱਚੇ ਨੂੰ ਤਸਵੀਰਾਂ ਦਿਖਾ ਕੇ ਸ਼ਬਦ ਸਿਖਾ ਰਹੇ ਹੋ। ਤੁਸੀਂ ਉਹਨਾਂ ਨੂੰ ਇੱਕ ਬਿੱਲੀ ਦੀ ਤਸਵੀਰ ਦਿਖਾਉਂਦੇ ਹੋ ਅਤੇ "ਬਿੱਲੀ" ਕਹਿੰਦੇ ਹੋ ਅਤੇ ਉਹ ਉਸ ਤਸਵੀਰ ਨੂੰ ਸ਼ਬਦ ਨਾਲ ਜੋੜਨਾ ਸਿੱਖਦੇ ਹਨ। ਇਸ ਤਰ੍ਹਾਂ ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ ਕੰਮ ਕਰਦੀ ਹੈ। ਮਾਡਲ ਨੂੰ ਬਹੁਤ ਸਾਰੇ ਟੈਕਸਟ ("ਤਸਵੀਰਾਂ") ਅਤੇ ਸੰਬੰਧਿਤ ਆਉਟਪੁੱਟ ("ਸ਼ਬਦ") ਦਿੱਤੇ ਜਾਂਦੇ ਹਨ, ਅਤੇ ਇਹ ਉਹਨਾਂ ਨੂੰ ਮੇਲਣਾ ਸਿੱਖਦਾ ਹੈ।
ਇਸ ਲਈ, ਜੇਕਰ ਤੁਸੀਂ ਇੱਕ LLM ਨੂੰ ਇੱਕ ਵਾਕ ਫੀਡ ਕਰਦੇ ਹੋ, ਤਾਂ ਇਹ ਅਗਲੇ ਸ਼ਬਦ ਜਾਂ ਵਾਕਾਂਸ਼ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ ਜੋ ਇਸ ਨੇ ਉਦਾਹਰਣਾਂ ਤੋਂ ਸਿੱਖਿਆ ਹੈ। ਇਸ ਤਰੀਕੇ ਨਾਲ, ਇਹ ਸਿੱਖਦਾ ਹੈ ਕਿ ਟੈਕਸਟ ਕਿਵੇਂ ਤਿਆਰ ਕਰਨਾ ਹੈ ਜੋ ਅਰਥ ਰੱਖਦਾ ਹੈ ਅਤੇ ਸੰਦਰਭ ਦੇ ਅਨੁਕੂਲ ਹੈ।
ਉਸ ਨੇ ਕਿਹਾ, ਕਈ ਵਾਰੀ ਐਲਐਲਐਮ ਵੀ ਥੋੜੀ ਜਿਹੀ ਨਿਰੀਖਣ ਰਹਿਤ ਸਿਖਲਾਈ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹਨ। ਇਹ ਬੱਚੇ ਨੂੰ ਵੱਖ-ਵੱਖ ਖਿਡੌਣਿਆਂ ਨਾਲ ਭਰੇ ਕਮਰੇ ਦੀ ਪੜਚੋਲ ਕਰਨ ਅਤੇ ਉਹਨਾਂ ਬਾਰੇ ਆਪਣੇ ਆਪ ਸਿੱਖਣ ਦੇਣ ਵਰਗਾ ਹੈ। ਮਾਡਲ ਬਿਨਾਂ ਲੇਬਲ ਕੀਤੇ ਡੇਟਾ, ਸਿੱਖਣ ਦੇ ਪੈਟਰਨਾਂ ਅਤੇ ਢਾਂਚਿਆਂ ਨੂੰ "ਸਹੀ" ਜਵਾਬ ਦੱਸੇ ਬਿਨਾਂ ਦੇਖਦਾ ਹੈ।
ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ, ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ ਦੇ ਉਲਟ, ਇਨਪੁੱਟ ਅਤੇ ਆਉਟਪੁੱਟ ਦੇ ਨਾਲ ਲੇਬਲ ਕੀਤੇ ਗਏ ਡੇਟਾ ਨੂੰ ਨਿਯੁਕਤ ਕਰਦੀ ਹੈ, ਜੋ ਲੇਬਲ ਕੀਤੇ ਆਉਟਪੁੱਟ ਡੇਟਾ ਦੀ ਵਰਤੋਂ ਨਹੀਂ ਕਰਦੀ ਹੈ।
ਸੰਖੇਪ ਰੂਪ ਵਿੱਚ, LLMs ਨੂੰ ਮੁੱਖ ਤੌਰ 'ਤੇ ਨਿਰੀਖਣ ਕੀਤੀ ਸਿਖਲਾਈ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ, ਪਰ ਉਹ ਆਪਣੀ ਸਮਰੱਥਾ ਨੂੰ ਵਧਾਉਣ ਲਈ, ਜਿਵੇਂ ਕਿ ਖੋਜੀ ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਅਯਾਮਤਾ ਘਟਾਉਣ ਲਈ ਵੀ ਨਿਰੀਖਣ ਰਹਿਤ ਸਿਖਲਾਈ ਦੀ ਵਰਤੋਂ ਕਰ ਸਕਦੇ ਹਨ।
ਇੱਕ ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣ ਲਈ ਡਾਟਾ ਵਾਲੀਅਮ (GB ਵਿੱਚ) ਕੀ ਜ਼ਰੂਰੀ ਹੈ?
ਸਪੀਚ ਡਾਟਾ ਮਾਨਤਾ ਅਤੇ ਵੌਇਸ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ ਸੰਭਾਵਨਾਵਾਂ ਦੀ ਦੁਨੀਆ ਬਹੁਤ ਜ਼ਿਆਦਾ ਹੈ, ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਕਈ ਉਦਯੋਗਾਂ ਵਿੱਚ ਐਪਲੀਕੇਸ਼ਨਾਂ ਦੀ ਬਹੁਤਾਤ ਲਈ ਵਰਤਿਆ ਜਾ ਰਿਹਾ ਹੈ।
ਇੱਕ ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣਾ ਇੱਕ-ਅਕਾਰ-ਫਿੱਟ-ਸਾਰੀ ਪ੍ਰਕਿਰਿਆ ਨਹੀਂ ਹੈ, ਖਾਸ ਤੌਰ 'ਤੇ ਜਦੋਂ ਲੋੜੀਂਦੇ ਡੇਟਾ ਦੀ ਗੱਲ ਆਉਂਦੀ ਹੈ। ਇਹ ਚੀਜ਼ਾਂ ਦੇ ਝੁੰਡ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ:
- ਮਾਡਲ ਡਿਜ਼ਾਈਨ.
- ਇਸ ਨੂੰ ਕੀ ਕੰਮ ਕਰਨ ਦੀ ਲੋੜ ਹੈ?
- ਡੇਟਾ ਦੀ ਕਿਸਮ ਜੋ ਤੁਸੀਂ ਵਰਤ ਰਹੇ ਹੋ।
- ਤੁਸੀਂ ਇਹ ਕਿੰਨਾ ਵਧੀਆ ਪ੍ਰਦਰਸ਼ਨ ਕਰਨਾ ਚਾਹੁੰਦੇ ਹੋ?
ਉਸ ਨੇ ਕਿਹਾ, LLM ਦੀ ਸਿਖਲਾਈ ਲਈ ਆਮ ਤੌਰ 'ਤੇ ਟੈਕਸਟ ਡੇਟਾ ਦੀ ਵੱਡੀ ਮਾਤਰਾ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ। ਪਰ ਅਸੀਂ ਕਿੰਨੇ ਵਿਸ਼ਾਲ ਬਾਰੇ ਗੱਲ ਕਰ ਰਹੇ ਹਾਂ? ਖੈਰ, ਗੀਗਾਬਾਈਟ (GB) ਤੋਂ ਪਰੇ ਸੋਚੋ। ਅਸੀਂ ਆਮ ਤੌਰ 'ਤੇ ਡੇਟਾ ਦੇ ਟੈਰਾਬਾਈਟ (ਟੀਬੀ) ਜਾਂ ਇੱਥੋਂ ਤੱਕ ਕਿ ਪੇਟਾਬਾਈਟ (ਪੀਬੀ) ਨੂੰ ਦੇਖ ਰਹੇ ਹਾਂ।
GPT-3 'ਤੇ ਗੌਰ ਕਰੋ, ਆਲੇ-ਦੁਆਲੇ ਦੇ ਸਭ ਤੋਂ ਵੱਡੇ LLM ਵਿੱਚੋਂ ਇੱਕ। ਇਸ 'ਤੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ 570 GB ਟੈਕਸਟ ਡਾਟਾ. ਛੋਟੇ LLM ਨੂੰ ਘੱਟ ਲੋੜ ਹੋ ਸਕਦੀ ਹੈ - ਸ਼ਾਇਦ 10-20 GB ਜਾਂ 1 GB ਗੀਗਾਬਾਈਟ - ਪਰ ਇਹ ਅਜੇ ਵੀ ਬਹੁਤ ਹੈ।

ਪਰ ਇਹ ਸਿਰਫ ਡੇਟਾ ਦੇ ਆਕਾਰ ਬਾਰੇ ਨਹੀਂ ਹੈ. ਗੁਣਵੱਤਾ ਵੀ ਮਹੱਤਵਪੂਰਨ ਹੈ. ਮਾਡਲ ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਸਿੱਖਣ ਵਿੱਚ ਮਦਦ ਕਰਨ ਲਈ ਡਾਟਾ ਸਾਫ਼ ਅਤੇ ਭਿੰਨ ਹੋਣ ਦੀ ਲੋੜ ਹੈ। ਅਤੇ ਤੁਸੀਂ ਬੁਝਾਰਤ ਦੇ ਹੋਰ ਮੁੱਖ ਭਾਗਾਂ ਨੂੰ ਨਹੀਂ ਭੁੱਲ ਸਕਦੇ, ਜਿਵੇਂ ਕਿ ਤੁਹਾਨੂੰ ਲੋੜੀਂਦੀ ਕੰਪਿਊਟਿੰਗ ਸ਼ਕਤੀ, ਸਿਖਲਾਈ ਲਈ ਤੁਹਾਡੇ ਦੁਆਰਾ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਐਲਗੋਰਿਦਮ, ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਹਾਰਡਵੇਅਰ ਸੈੱਟਅੱਪ। ਇਹ ਸਾਰੇ ਕਾਰਕ LLM ਦੀ ਸਿਖਲਾਈ ਵਿੱਚ ਇੱਕ ਵੱਡੀ ਭੂਮਿਕਾ ਨਿਭਾਉਂਦੇ ਹਨ।
ਵੱਡੀ ਭਾਸ਼ਾ ਦੇ ਮਾਡਲਾਂ ਦਾ ਉਭਾਰ: ਉਹ ਮਾਇਨੇ ਕਿਉਂ ਰੱਖਦੇ ਹਨ
LLM ਹੁਣ ਸਿਰਫ਼ ਇੱਕ ਸੰਕਲਪ ਜਾਂ ਇੱਕ ਪ੍ਰਯੋਗ ਨਹੀਂ ਰਹੇ ਹਨ। ਉਹ ਸਾਡੇ ਡਿਜੀਟਲ ਲੈਂਡਸਕੇਪ ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਇੱਕ ਮਹੱਤਵਪੂਰਨ ਭੂਮਿਕਾ ਨਿਭਾ ਰਹੇ ਹਨ। ਪਰ ਅਜਿਹਾ ਕਿਉਂ ਹੋ ਰਿਹਾ ਹੈ? ਕੀ ਇਹਨਾਂ LLM ਨੂੰ ਇੰਨਾ ਮਹੱਤਵਪੂਰਨ ਬਣਾਉਂਦਾ ਹੈ? ਆਓ ਕੁਝ ਮੁੱਖ ਕਾਰਕਾਂ ਦੀ ਖੋਜ ਕਰੀਏ।
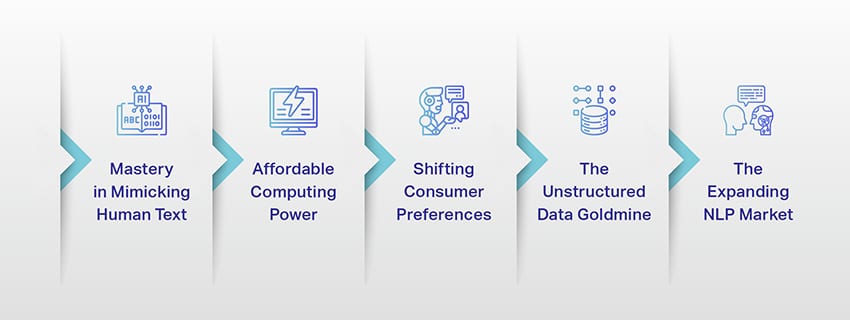
ਮਨੁੱਖੀ ਟੈਕਸਟ ਦੀ ਨਕਲ ਕਰਨ ਵਿੱਚ ਮੁਹਾਰਤ
LLM ਨੇ ਭਾਸ਼ਾ-ਅਧਾਰਿਤ ਕੰਮਾਂ ਨੂੰ ਸੰਭਾਲਣ ਦੇ ਤਰੀਕੇ ਨੂੰ ਬਦਲ ਦਿੱਤਾ ਹੈ। ਮਜਬੂਤ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਐਲਗੋਰਿਦਮ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਬਣਾਏ ਗਏ, ਇਹ ਮਾਡਲ ਮਨੁੱਖੀ ਭਾਸ਼ਾ ਦੀਆਂ ਬਾਰੀਕੀਆਂ ਨੂੰ ਸਮਝਣ ਦੀ ਸਮਰੱਥਾ ਨਾਲ ਲੈਸ ਹਨ, ਜਿਸ ਵਿੱਚ ਸੰਦਰਭ, ਭਾਵਨਾ, ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ ਵਿਅੰਗ ਵੀ ਸ਼ਾਮਲ ਹੈ, ਕੁਝ ਹੱਦ ਤੱਕ। ਮਨੁੱਖੀ ਭਾਸ਼ਾ ਦੀ ਨਕਲ ਕਰਨ ਦੀ ਇਹ ਸਮਰੱਥਾ ਕੇਵਲ ਇੱਕ ਨਵੀਨਤਾ ਨਹੀਂ ਹੈ, ਇਸਦੇ ਮਹੱਤਵਪੂਰਨ ਪ੍ਰਭਾਵ ਹਨ।
LLMs ਦੀਆਂ ਉੱਨਤ ਟੈਕਸਟ ਜਨਰੇਸ਼ਨ ਯੋਗਤਾਵਾਂ ਸਮੱਗਰੀ ਬਣਾਉਣ ਤੋਂ ਲੈ ਕੇ ਗਾਹਕ ਸੇਵਾ ਇੰਟਰੈਕਸ਼ਨਾਂ ਤੱਕ ਹਰ ਚੀਜ਼ ਨੂੰ ਵਧਾ ਸਕਦੀਆਂ ਹਨ।
ਇੱਕ ਡਿਜ਼ੀਟਲ ਸਹਾਇਕ ਨੂੰ ਇੱਕ ਗੁੰਝਲਦਾਰ ਸਵਾਲ ਪੁੱਛਣ ਅਤੇ ਇੱਕ ਜਵਾਬ ਪ੍ਰਾਪਤ ਕਰਨ ਦੇ ਯੋਗ ਹੋਣ ਦੀ ਕਲਪਨਾ ਕਰੋ ਜੋ ਨਾ ਸਿਰਫ਼ ਅਰਥ ਰੱਖਦਾ ਹੈ, ਸਗੋਂ ਇੱਕ ਸੰਵਾਦਪੂਰਨ ਟੋਨ ਵਿੱਚ ਸੁਮੇਲ, ਢੁਕਵਾਂ ਅਤੇ ਪ੍ਰਦਾਨ ਵੀ ਕਰਦਾ ਹੈ। ਇਹ ਉਹ ਹੈ ਜੋ ਐਲਐਲਐਮ ਯੋਗ ਕਰ ਰਹੇ ਹਨ। ਉਹ ਵਧੇਰੇ ਅਨੁਭਵੀ ਅਤੇ ਮਨਮੋਹਕ ਮਨੁੱਖੀ-ਮਸ਼ੀਨ ਦੇ ਆਪਸੀ ਤਾਲਮੇਲ ਨੂੰ ਵਧਾ ਰਹੇ ਹਨ, ਉਪਭੋਗਤਾ ਅਨੁਭਵਾਂ ਨੂੰ ਭਰਪੂਰ ਬਣਾ ਰਹੇ ਹਨ, ਅਤੇ ਜਾਣਕਾਰੀ ਤੱਕ ਪਹੁੰਚ ਨੂੰ ਜਮਹੂਰੀ ਬਣਾ ਰਹੇ ਹਨ।
ਕਿਫਾਇਤੀ ਕੰਪਿਊਟਿੰਗ ਪਾਵਰ
LLM ਦਾ ਉਭਾਰ ਕੰਪਿਊਟਿੰਗ ਦੇ ਖੇਤਰ ਵਿੱਚ ਸਮਾਨਾਂਤਰ ਵਿਕਾਸ ਤੋਂ ਬਿਨਾਂ ਸੰਭਵ ਨਹੀਂ ਸੀ। ਵਧੇਰੇ ਖਾਸ ਤੌਰ 'ਤੇ, ਕੰਪਿਊਟੇਸ਼ਨਲ ਸਰੋਤਾਂ ਦੇ ਲੋਕਤੰਤਰੀਕਰਨ ਨੇ ਐਲਐਲਐਮ ਦੇ ਵਿਕਾਸ ਅਤੇ ਗੋਦ ਲੈਣ ਵਿੱਚ ਮਹੱਤਵਪੂਰਨ ਭੂਮਿਕਾ ਨਿਭਾਈ ਹੈ।
ਕਲਾਉਡ-ਅਧਾਰਿਤ ਪਲੇਟਫਾਰਮ ਉੱਚ-ਪ੍ਰਦਰਸ਼ਨ ਵਾਲੇ ਕੰਪਿਊਟਿੰਗ ਸਰੋਤਾਂ ਤੱਕ ਬੇਮਿਸਾਲ ਪਹੁੰਚ ਦੀ ਪੇਸ਼ਕਸ਼ ਕਰ ਰਹੇ ਹਨ। ਇਸ ਤਰ੍ਹਾਂ, ਇੱਥੋਂ ਤੱਕ ਕਿ ਛੋਟੇ ਪੱਧਰ ਦੀਆਂ ਸੰਸਥਾਵਾਂ ਅਤੇ ਸੁਤੰਤਰ ਖੋਜਕਰਤਾ ਵੀ ਆਧੁਨਿਕ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਮਾਡਲਾਂ ਨੂੰ ਸਿਖਲਾਈ ਦੇ ਸਕਦੇ ਹਨ।
ਇਸ ਤੋਂ ਇਲਾਵਾ, ਪ੍ਰੋਸੈਸਿੰਗ ਯੂਨਿਟਾਂ (ਜਿਵੇਂ ਕਿ GPUs ਅਤੇ TPUs) ਵਿੱਚ ਸੁਧਾਰ, ਡਿਸਟਰੀਬਿਊਟਿਡ ਕੰਪਿਊਟਿੰਗ ਦੇ ਉਭਾਰ ਦੇ ਨਾਲ, ਅਰਬਾਂ ਪੈਰਾਮੀਟਰਾਂ ਵਾਲੇ ਮਾਡਲਾਂ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣਾ ਸੰਭਵ ਬਣਾ ਦਿੱਤਾ ਹੈ। ਕੰਪਿਊਟਿੰਗ ਪਾਵਰ ਦੀ ਇਹ ਵਧੀ ਹੋਈ ਪਹੁੰਚਯੋਗਤਾ LLMs ਦੇ ਵਿਕਾਸ ਅਤੇ ਸਫਲਤਾ ਨੂੰ ਸਮਰੱਥ ਬਣਾ ਰਹੀ ਹੈ, ਜਿਸ ਨਾਲ ਖੇਤਰ ਵਿੱਚ ਹੋਰ ਨਵੀਨਤਾ ਅਤੇ ਐਪਲੀਕੇਸ਼ਨ ਹਨ।
ਖਪਤਕਾਰਾਂ ਦੀਆਂ ਤਰਜੀਹਾਂ ਨੂੰ ਬਦਲਣਾ
ਅੱਜ ਖਪਤਕਾਰ ਸਿਰਫ਼ ਜਵਾਬ ਨਹੀਂ ਚਾਹੁੰਦੇ ਹਨ; ਉਹ ਰੁਝੇਵੇਂ ਅਤੇ ਸੰਬੰਧਤ ਪਰਸਪਰ ਪ੍ਰਭਾਵ ਚਾਹੁੰਦੇ ਹਨ। ਜਿਵੇਂ-ਜਿਵੇਂ ਜ਼ਿਆਦਾ ਲੋਕ ਡਿਜੀਟਲ ਟੈਕਨਾਲੋਜੀ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਵੱਡੇ ਹੁੰਦੇ ਹਨ, ਇਹ ਸਪੱਸ਼ਟ ਹੁੰਦਾ ਹੈ ਕਿ ਵਧੇਰੇ ਕੁਦਰਤੀ ਅਤੇ ਮਨੁੱਖਾਂ ਵਰਗੀ ਮਹਿਸੂਸ ਕਰਨ ਵਾਲੀ ਤਕਨਾਲੋਜੀ ਦੀ ਲੋੜ ਵਧਦੀ ਜਾ ਰਹੀ ਹੈ। LLM ਇਹਨਾਂ ਉਮੀਦਾਂ ਨੂੰ ਪੂਰਾ ਕਰਨ ਲਈ ਇੱਕ ਬੇਮਿਸਾਲ ਮੌਕਾ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ। ਮਨੁੱਖੀ-ਵਰਗੇ ਟੈਕਸਟ ਤਿਆਰ ਕਰਕੇ, ਇਹ ਮਾਡਲ ਆਕਰਸ਼ਕ ਅਤੇ ਗਤੀਸ਼ੀਲ ਡਿਜੀਟਲ ਅਨੁਭਵ ਬਣਾ ਸਕਦੇ ਹਨ, ਜੋ ਉਪਭੋਗਤਾ ਦੀ ਸੰਤੁਸ਼ਟੀ ਅਤੇ ਵਫ਼ਾਦਾਰੀ ਨੂੰ ਵਧਾ ਸਕਦੇ ਹਨ। ਚਾਹੇ ਇਹ ਗਾਹਕ ਸੇਵਾ ਪ੍ਰਦਾਨ ਕਰਨ ਵਾਲੇ AI ਚੈਟਬੋਟਸ ਹਨ ਜਾਂ ਖਬਰਾਂ ਦੇ ਅਪਡੇਟਸ ਪ੍ਰਦਾਨ ਕਰਨ ਵਾਲੇ ਵੌਇਸ ਅਸਿਸਟੈਂਟ, LLMs AI ਦੇ ਇੱਕ ਯੁੱਗ ਦੀ ਸ਼ੁਰੂਆਤ ਕਰ ਰਹੇ ਹਨ ਜੋ ਸਾਨੂੰ ਬਿਹਤਰ ਸਮਝਦਾ ਹੈ।
ਗੈਰ-ਸੰਗਠਿਤ ਡੇਟਾ ਗੋਲਡਮਾਈਨ
ਗੈਰ-ਸੰਗਠਿਤ ਡੇਟਾ, ਜਿਵੇਂ ਕਿ ਈਮੇਲਾਂ, ਸੋਸ਼ਲ ਮੀਡੀਆ ਪੋਸਟਾਂ, ਅਤੇ ਗਾਹਕ ਸਮੀਖਿਆਵਾਂ, ਸੂਝ ਦਾ ਖਜ਼ਾਨਾ ਹੈ। ਇਹ ਅੰਦਾਜ਼ਾ ਹੈ ਕਿ ਵੱਧ 80% ਦੀ ਦਰ ਨਾਲ ਐਂਟਰਪ੍ਰਾਈਜ਼ ਡੇਟਾ ਗੈਰ-ਸੰਗਠਿਤ ਹੈ ਅਤੇ ਵਧ ਰਿਹਾ ਹੈ 55% ਪ੍ਰਤੀ ਸਾਲ. ਇਹ ਡੇਟਾ ਕਾਰੋਬਾਰਾਂ ਲਈ ਸੋਨੇ ਦੀ ਖਾਨ ਹੈ ਜੇਕਰ ਸਹੀ ਢੰਗ ਨਾਲ ਲਾਭ ਉਠਾਇਆ ਜਾਵੇ।
LLMs ਇੱਥੇ ਖੇਡ ਵਿੱਚ ਆਉਂਦੇ ਹਨ, ਉਹਨਾਂ ਦੀ ਪ੍ਰੋਸੈਸ ਕਰਨ ਅਤੇ ਪੈਮਾਨੇ 'ਤੇ ਅਜਿਹੇ ਡੇਟਾ ਨੂੰ ਸਮਝਣ ਦੀ ਯੋਗਤਾ ਦੇ ਨਾਲ। ਉਹ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ, ਟੈਕਸਟ ਵਰਗੀਕਰਨ, ਜਾਣਕਾਰੀ ਕੱਢਣ, ਅਤੇ ਹੋਰ ਬਹੁਤ ਸਾਰੇ ਕੰਮਾਂ ਨੂੰ ਸੰਭਾਲ ਸਕਦੇ ਹਨ, ਇਸ ਤਰ੍ਹਾਂ ਕੀਮਤੀ ਸੂਝ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ।
ਭਾਵੇਂ ਇਹ ਸੋਸ਼ਲ ਮੀਡੀਆ ਪੋਸਟਾਂ ਤੋਂ ਰੁਝਾਨਾਂ ਦੀ ਪਛਾਣ ਕਰਨਾ ਹੋਵੇ ਜਾਂ ਸਮੀਖਿਆਵਾਂ ਤੋਂ ਗਾਹਕ ਭਾਵਨਾਵਾਂ ਦਾ ਪਤਾ ਲਗਾਉਣਾ ਹੋਵੇ, LLM ਕਾਰੋਬਾਰਾਂ ਨੂੰ ਵੱਡੀ ਮਾਤਰਾ ਵਿੱਚ ਗੈਰ-ਸੰਗਠਿਤ ਡੇਟਾ ਨੂੰ ਨੈਵੀਗੇਟ ਕਰਨ ਅਤੇ ਡੇਟਾ-ਅਧਾਰਿਤ ਫੈਸਲੇ ਲੈਣ ਵਿੱਚ ਮਦਦ ਕਰ ਰਹੇ ਹਨ।
ਐਨਐਲਪੀ ਮਾਰਕੀਟ ਦਾ ਵਿਸਤਾਰ
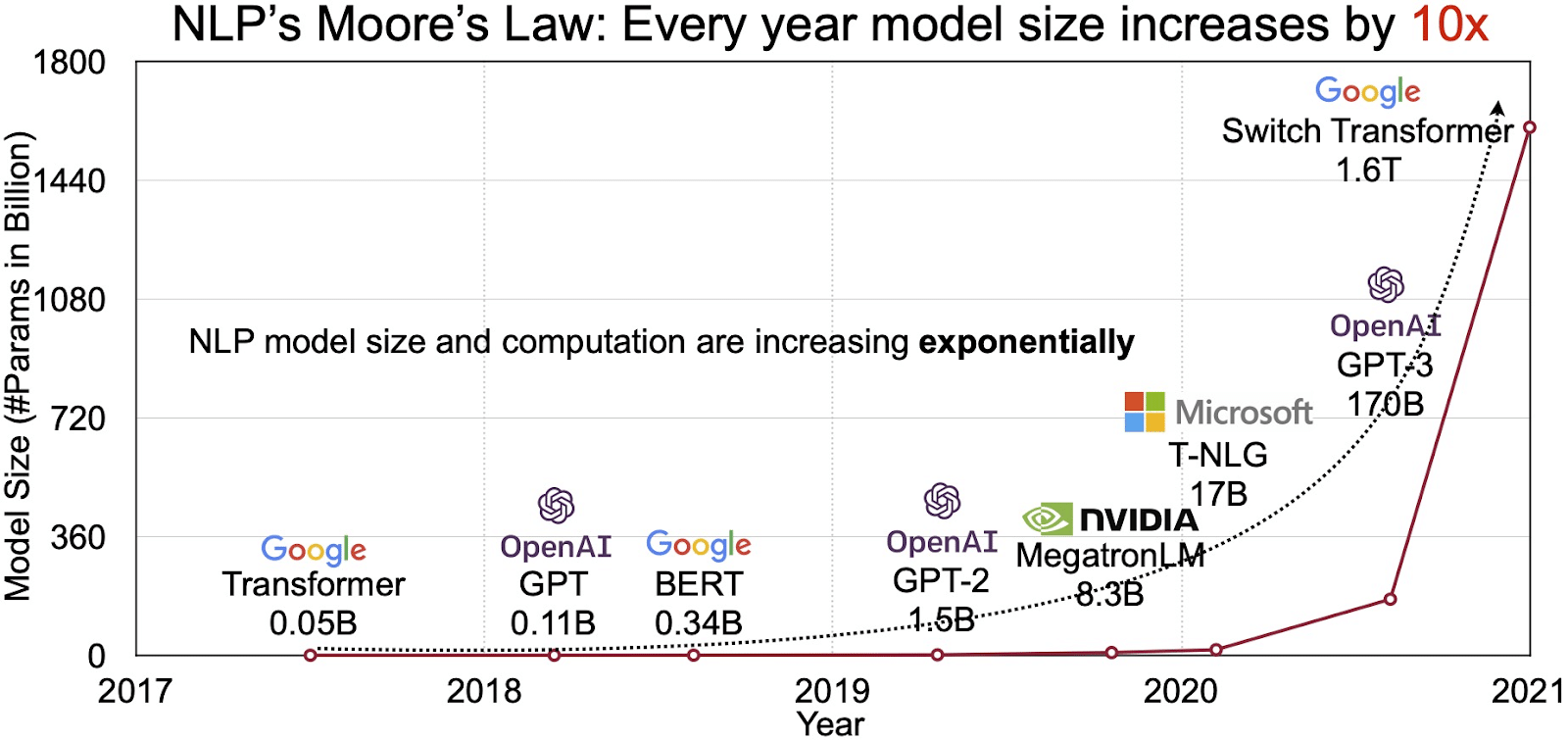
ਐਲਐਲਐਮ ਦੀ ਸੰਭਾਵਨਾ ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਪ੍ਰੋਸੈਸਿੰਗ (ਐਨਐਲਪੀ) ਲਈ ਤੇਜ਼ੀ ਨਾਲ ਵਧ ਰਹੇ ਬਾਜ਼ਾਰ ਵਿੱਚ ਪ੍ਰਤੀਬਿੰਬਤ ਹੁੰਦੀ ਹੈ। ਵਿਸ਼ਲੇਸ਼ਕ ਐਨਐਲਪੀ ਮਾਰਕੀਟ ਤੋਂ ਵਿਸਤਾਰ ਕਰਨ ਲਈ ਪ੍ਰੋਜੈਕਟ ਕਰਦੇ ਹਨ 11 ਵਿੱਚ $2020 ਬਿਲੀਅਨ ਤੋਂ 35 ਤੱਕ $2026 ਬਿਲੀਅਨ ਤੋਂ ਵੱਧ. ਪਰ ਇਹ ਸਿਰਫ ਮਾਰਕੀਟ ਦਾ ਆਕਾਰ ਨਹੀਂ ਹੈ ਜੋ ਫੈਲ ਰਿਹਾ ਹੈ. ਮਾਡਲ ਖੁਦ ਵੀ ਵਧ ਰਹੇ ਹਨ, ਦੋਵੇਂ ਭੌਤਿਕ ਆਕਾਰ ਅਤੇ ਮਾਪਦੰਡਾਂ ਦੀ ਸੰਖਿਆ ਵਿੱਚ ਜੋ ਉਹ ਸੰਭਾਲਦੇ ਹਨ। ਸਾਲਾਂ ਦੌਰਾਨ ਐਲਐਲਐਮ ਦਾ ਵਿਕਾਸ, ਜਿਵੇਂ ਕਿ ਹੇਠਾਂ ਦਿੱਤੇ ਚਿੱਤਰ (ਚਿੱਤਰ ਸਰੋਤ: ਲਿੰਕ) ਵਿੱਚ ਦੇਖਿਆ ਗਿਆ ਹੈ, ਉਹਨਾਂ ਦੀ ਵਧਦੀ ਜਟਿਲਤਾ ਅਤੇ ਸਮਰੱਥਾ ਨੂੰ ਰੇਖਾਂਕਿਤ ਕਰਦਾ ਹੈ।
ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲਾਂ ਦੇ ਪ੍ਰਸਿੱਧ ਵਰਤੋਂ ਦੇ ਮਾਮਲੇ
ਇੱਥੇ LLM ਦੇ ਕੁਝ ਪ੍ਰਮੁੱਖ ਅਤੇ ਸਭ ਤੋਂ ਵੱਧ ਪ੍ਰਚਲਿਤ ਵਰਤੋਂ ਦੇ ਮਾਮਲੇ ਹਨ:
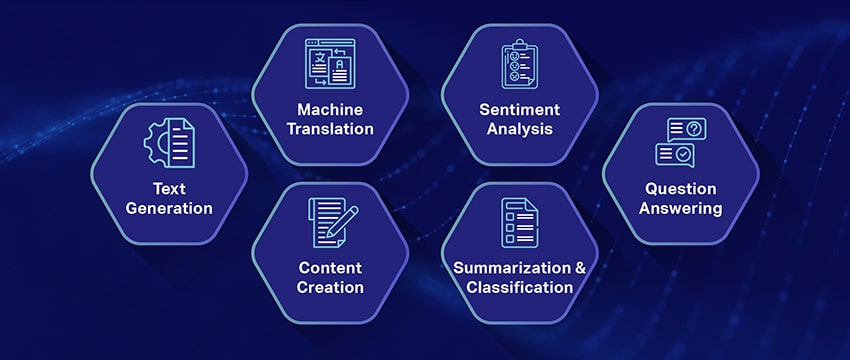
- ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਦਾ ਪਾਠ ਤਿਆਰ ਕਰਨਾ: ਵੱਡੇ ਭਾਸ਼ਾ ਮਾਡਲ (LLMs) ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਵਿੱਚ ਲਿਖਤਾਂ ਨੂੰ ਖੁਦਮੁਖਤਿਆਰੀ ਨਾਲ ਤਿਆਰ ਕਰਨ ਲਈ ਨਕਲੀ ਬੁੱਧੀ ਅਤੇ ਕੰਪਿਊਟੇਸ਼ਨਲ ਭਾਸ਼ਾ ਵਿਗਿਆਨ ਦੀ ਸ਼ਕਤੀ ਨੂੰ ਜੋੜਦੇ ਹਨ। ਉਹ ਉਪਭੋਗਤਾਵਾਂ ਦੀਆਂ ਵਿਭਿੰਨ ਜ਼ਰੂਰਤਾਂ ਨੂੰ ਪੂਰਾ ਕਰ ਸਕਦੇ ਹਨ ਜਿਵੇਂ ਕਿ ਲੇਖ ਲਿਖਣਾ, ਗਾਣੇ ਬਣਾਉਣਾ, ਜਾਂ ਉਪਭੋਗਤਾਵਾਂ ਨਾਲ ਗੱਲਬਾਤ ਵਿੱਚ ਸ਼ਾਮਲ ਹੋਣਾ।
- ਮਸ਼ੀਨਾਂ ਰਾਹੀਂ ਅਨੁਵਾਦ: ਕਿਸੇ ਵੀ ਜੋੜੇ ਦੀਆਂ ਭਾਸ਼ਾਵਾਂ ਵਿਚਕਾਰ ਟੈਕਸਟ ਦਾ ਅਨੁਵਾਦ ਕਰਨ ਲਈ LLMs ਨੂੰ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਲਗਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। ਇਹ ਮਾਡਲ ਸਰੋਤ ਅਤੇ ਨਿਸ਼ਾਨਾ ਦੋਵਾਂ ਭਾਸ਼ਾਵਾਂ ਦੀ ਭਾਸ਼ਾਈ ਬਣਤਰ ਨੂੰ ਸਮਝਣ ਲਈ ਡੂੰਘੇ ਸਿੱਖਣ ਦੇ ਐਲਗੋਰਿਦਮ ਦਾ ਸ਼ੋਸ਼ਣ ਕਰਦੇ ਹਨ, ਜਿਸ ਨਾਲ ਸਰੋਤ ਟੈਕਸਟ ਨੂੰ ਲੋੜੀਂਦੀ ਭਾਸ਼ਾ ਵਿੱਚ ਅਨੁਵਾਦ ਕਰਨ ਦੀ ਸਹੂਲਤ ਮਿਲਦੀ ਹੈ।
- ਮੂਲ ਸਮੱਗਰੀ ਤਿਆਰ ਕਰਨਾ: LLMs ਨੇ ਮਸ਼ੀਨਾਂ ਲਈ ਇਕਸੁਰਤਾ ਅਤੇ ਤਰਕਪੂਰਨ ਸਮੱਗਰੀ ਤਿਆਰ ਕਰਨ ਦੇ ਰਸਤੇ ਖੋਲ੍ਹ ਦਿੱਤੇ ਹਨ। ਇਸ ਸਮੱਗਰੀ ਦੀ ਵਰਤੋਂ ਬਲੌਗ ਪੋਸਟਾਂ, ਲੇਖਾਂ ਅਤੇ ਹੋਰ ਕਿਸਮਾਂ ਦੀ ਸਮੱਗਰੀ ਬਣਾਉਣ ਲਈ ਕੀਤੀ ਜਾ ਸਕਦੀ ਹੈ। ਮਾਡਲ ਇੱਕ ਨਾਵਲ ਅਤੇ ਉਪਭੋਗਤਾ-ਅਨੁਕੂਲ ਢੰਗ ਨਾਲ ਸਮੱਗਰੀ ਨੂੰ ਫਾਰਮੈਟ ਅਤੇ ਸੰਰਚਨਾ ਕਰਨ ਲਈ ਉਹਨਾਂ ਦੇ ਡੂੰਘੇ ਡੂੰਘੇ-ਸਿੱਖਣ ਦੇ ਅਨੁਭਵ ਵਿੱਚ ਟੈਪ ਕਰਦੇ ਹਨ।
- ਭਾਵਨਾਵਾਂ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨਾ: ਵੱਡੀ ਭਾਸ਼ਾ ਦੇ ਮਾਡਲਾਂ ਦੀ ਇੱਕ ਦਿਲਚਸਪ ਐਪਲੀਕੇਸ਼ਨ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਹੈ। ਇਸ ਵਿੱਚ, ਮਾਡਲ ਨੂੰ ਵਿਆਖਿਆਤਮਿਕ ਪਾਠ ਵਿੱਚ ਮੌਜੂਦ ਭਾਵਨਾਤਮਕ ਅਵਸਥਾਵਾਂ ਅਤੇ ਭਾਵਨਾਵਾਂ ਨੂੰ ਪਛਾਣਨ ਅਤੇ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨ ਲਈ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ। ਸਾਫਟਵੇਅਰ ਸਕਾਰਾਤਮਕਤਾ, ਨਕਾਰਾਤਮਕਤਾ, ਨਿਰਪੱਖਤਾ, ਅਤੇ ਹੋਰ ਗੁੰਝਲਦਾਰ ਭਾਵਨਾਵਾਂ ਵਰਗੀਆਂ ਭਾਵਨਾਵਾਂ ਦੀ ਪਛਾਣ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਗਾਹਕ ਫੀਡਬੈਕ ਅਤੇ ਵੱਖ-ਵੱਖ ਉਤਪਾਦਾਂ ਅਤੇ ਸੇਵਾਵਾਂ ਬਾਰੇ ਵਿਚਾਰਾਂ ਵਿੱਚ ਕੀਮਤੀ ਸੂਝ ਪ੍ਰਦਾਨ ਕਰ ਸਕਦਾ ਹੈ।
- ਪਾਠ ਨੂੰ ਸਮਝਣਾ, ਸੰਖੇਪ ਕਰਨਾ ਅਤੇ ਵਰਗੀਕਰਨ ਕਰਨਾ: LLM ਟੈਕਸਟ ਅਤੇ ਇਸਦੇ ਸੰਦਰਭ ਦੀ ਵਿਆਖਿਆ ਕਰਨ ਲਈ AI ਸੌਫਟਵੇਅਰ ਲਈ ਇੱਕ ਵਿਹਾਰਕ ਢਾਂਚਾ ਸਥਾਪਤ ਕਰਦੇ ਹਨ। ਮਾਡਲ ਨੂੰ ਵੱਡੀ ਮਾਤਰਾ ਵਿੱਚ ਡੇਟਾ ਨੂੰ ਸਮਝਣ ਅਤੇ ਪੜਤਾਲ ਕਰਨ ਲਈ ਨਿਰਦੇਸ਼ ਦੇ ਕੇ, LLM AI ਮਾਡਲਾਂ ਨੂੰ ਵਿਭਿੰਨ ਰੂਪਾਂ ਅਤੇ ਪੈਟਰਨਾਂ ਵਿੱਚ ਟੈਕਸਟ ਨੂੰ ਸਮਝਣ, ਸੰਖੇਪ ਕਰਨ ਅਤੇ ਇੱਥੋਂ ਤੱਕ ਕਿ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ।
- ਸਵਾਲਾਂ ਦਾ ਜਵਾਬ ਦੇਣਾ: ਵੱਡੇ ਭਾਸ਼ਾ ਦੇ ਮਾਡਲ ਪ੍ਰਸ਼ਨ ਉੱਤਰ (QA) ਪ੍ਰਣਾਲੀਆਂ ਨੂੰ ਉਪਭੋਗਤਾ ਦੀ ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਦੀ ਪੁੱਛਗਿੱਛ ਨੂੰ ਸਹੀ ਢੰਗ ਨਾਲ ਸਮਝਣ ਅਤੇ ਜਵਾਬ ਦੇਣ ਦੀ ਸਮਰੱਥਾ ਨਾਲ ਲੈਸ ਕਰਦੇ ਹਨ। ਇਸ ਵਰਤੋਂ ਦੇ ਕੇਸ ਦੀਆਂ ਪ੍ਰਸਿੱਧ ਉਦਾਹਰਨਾਂ ਵਿੱਚ ChatGPT ਅਤੇ BERT ਸ਼ਾਮਲ ਹਨ, ਜੋ ਕਿ ਇੱਕ ਸਵਾਲ ਦੇ ਸੰਦਰਭ ਦੀ ਜਾਂਚ ਕਰਦੇ ਹਨ ਅਤੇ ਉਪਭੋਗਤਾ ਸਵਾਲਾਂ ਦੇ ਸੰਬੰਧਿਤ ਜਵਾਬ ਪ੍ਰਦਾਨ ਕਰਨ ਲਈ ਟੈਕਸਟ ਦੇ ਇੱਕ ਵਿਸ਼ਾਲ ਸੰਗ੍ਰਹਿ ਦੀ ਜਾਂਚ ਕਰਦੇ ਹਨ।

ਪਾਰਟ-ਆਫ-ਸਪੀਚ (POS) ਟੈਗਿੰਗ
ਵਾਕਾਂ ਵਿੱਚ ਸ਼ਬਦਾਂ ਨੂੰ ਉਹਨਾਂ ਦੇ ਵਿਆਕਰਨਿਕ ਫੰਕਸ਼ਨ ਨਾਲ ਟੈਗ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਜਿਵੇਂ ਕਿ ਕਿਰਿਆਵਾਂ, ਨਾਂਵਾਂ, ਵਿਸ਼ੇਸ਼ਣਾਂ, ਆਦਿ। ਇਹ ਪ੍ਰਕਿਰਿਆ ਮਾਡਲ ਨੂੰ ਵਿਆਕਰਣ ਅਤੇ ਸ਼ਬਦਾਂ ਵਿਚਕਾਰ ਸਬੰਧਾਂ ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਸਹਾਇਤਾ ਕਰਦੀ ਹੈ।

ਨਾਮੀ ਇਕਾਈ ਮਾਨਤਾ (NER)
ਇੱਕ ਵਾਕ ਦੇ ਅੰਦਰ ਸੰਸਥਾਵਾਂ, ਸਥਾਨਾਂ ਅਤੇ ਲੋਕਾਂ ਵਰਗੀਆਂ ਨਾਮਿਤ ਸੰਸਥਾਵਾਂ ਨੂੰ ਚਿੰਨ੍ਹਿਤ ਕੀਤਾ ਗਿਆ ਹੈ। ਇਹ ਅਭਿਆਸ ਮਾਡਲ ਨੂੰ ਸ਼ਬਦਾਂ ਅਤੇ ਵਾਕਾਂਸ਼ਾਂ ਦੇ ਅਰਥਾਂ ਦੇ ਅਰਥਾਂ ਦੀ ਵਿਆਖਿਆ ਕਰਨ ਵਿੱਚ ਸਹਾਇਤਾ ਕਰਦਾ ਹੈ ਅਤੇ ਵਧੇਰੇ ਸਟੀਕ ਜਵਾਬ ਪ੍ਰਦਾਨ ਕਰਦਾ ਹੈ।

ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ
ਟੈਕਸਟ ਡੇਟਾ ਨੂੰ ਸਕਾਰਾਤਮਕ, ਨਿਰਪੱਖ, ਜਾਂ ਨਕਾਰਾਤਮਕ ਵਰਗੇ ਭਾਵਨਾਤਮਕ ਲੇਬਲ ਨਿਰਧਾਰਤ ਕੀਤੇ ਜਾਂਦੇ ਹਨ, ਮਾਡਲ ਨੂੰ ਵਾਕਾਂ ਦੇ ਭਾਵਨਾਤਮਕ ਰੂਪ ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਮਦਦ ਕਰਦੇ ਹਨ। ਇਹ ਭਾਵਨਾਵਾਂ ਅਤੇ ਵਿਚਾਰਾਂ ਨੂੰ ਸ਼ਾਮਲ ਕਰਨ ਵਾਲੇ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣ ਲਈ ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਲਾਭਦਾਇਕ ਹੈ।
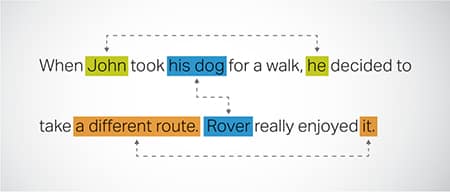
ਕੋਰ ਰੈਜ਼ੋਲਿਊਸ਼ਨ
ਉਹਨਾਂ ਉਦਾਹਰਣਾਂ ਦੀ ਪਛਾਣ ਕਰਨਾ ਅਤੇ ਹੱਲ ਕਰਨਾ ਜਿੱਥੇ ਇੱਕ ਟੈਕਸਟ ਦੇ ਵੱਖ-ਵੱਖ ਹਿੱਸਿਆਂ ਵਿੱਚ ਇੱਕੋ ਇਕਾਈ ਦਾ ਹਵਾਲਾ ਦਿੱਤਾ ਜਾਂਦਾ ਹੈ। ਇਹ ਕਦਮ ਮਾਡਲ ਨੂੰ ਵਾਕ ਦੇ ਸੰਦਰਭ ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ, ਇਸ ਤਰ੍ਹਾਂ ਇਕਸਾਰ ਜਵਾਬਾਂ ਵੱਲ ਅਗਵਾਈ ਕਰਦਾ ਹੈ।
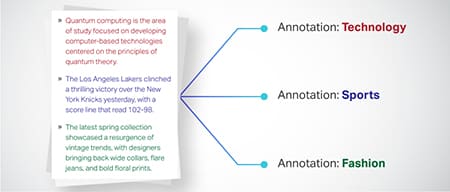
ਟੈਕਸਟ ਵਰਗੀਕਰਨ
ਟੈਕਸਟ ਡੇਟਾ ਨੂੰ ਪੂਰਵ-ਪ੍ਰਭਾਸ਼ਿਤ ਸਮੂਹਾਂ ਵਿੱਚ ਸ਼੍ਰੇਣੀਬੱਧ ਕੀਤਾ ਗਿਆ ਹੈ ਜਿਵੇਂ ਉਤਪਾਦ ਸਮੀਖਿਆਵਾਂ ਜਾਂ ਖਬਰਾਂ ਦੇ ਲੇਖ। ਇਹ ਟੈਕਸਟ ਦੀ ਸ਼ੈਲੀ ਜਾਂ ਵਿਸ਼ੇ ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਮਾਡਲ ਦੀ ਮਦਦ ਕਰਦਾ ਹੈ, ਵਧੇਰੇ ਢੁਕਵੇਂ ਜਵਾਬ ਪੈਦਾ ਕਰਦਾ ਹੈ।
ਸ਼ੈਪ ਦੀ ਭੇਟ
ਸਿਪ ਸੰਸਥਾਵਾਂ ਨੂੰ ਉਹਨਾਂ ਦੇ ਡੇਟਾ ਦਾ ਪ੍ਰਬੰਧਨ, ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਵੱਧ ਤੋਂ ਵੱਧ ਲਾਭ ਉਠਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਨ ਲਈ ਸੇਵਾਵਾਂ ਦੀ ਇੱਕ ਵਿਸ਼ਾਲ ਸ਼੍ਰੇਣੀ ਦੀ ਪੇਸ਼ਕਸ਼ ਕਰਦਾ ਹੈ।
ਡਾਟਾ ਵੈੱਬ-ਸਕ੍ਰੈਪਿੰਗ
ਸ਼ੈਪ ਦੁਆਰਾ ਪੇਸ਼ ਕੀਤੀ ਗਈ ਇੱਕ ਮੁੱਖ ਸੇਵਾ ਡੇਟਾ ਸਕ੍ਰੈਪਿੰਗ ਹੈ. ਇਸ ਵਿੱਚ ਡੋਮੇਨ-ਵਿਸ਼ੇਸ਼ URL ਤੋਂ ਡੇਟਾ ਨੂੰ ਕੱਢਣਾ ਸ਼ਾਮਲ ਹੈ। ਸਵੈਚਲਿਤ ਸਾਧਨਾਂ ਅਤੇ ਤਕਨੀਕਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ, ਸ਼ੈਪ ਵੱਖ-ਵੱਖ ਵੈੱਬਸਾਈਟਾਂ, ਉਤਪਾਦ ਮੈਨੂਅਲ, ਤਕਨੀਕੀ ਦਸਤਾਵੇਜ਼, ਔਨਲਾਈਨ ਫੋਰਮਾਂ, ਔਨਲਾਈਨ ਸਮੀਖਿਆਵਾਂ, ਗਾਹਕ ਸੇਵਾ ਡੇਟਾ, ਉਦਯੋਗ ਰੈਗੂਲੇਟਰੀ ਦਸਤਾਵੇਜ਼ ਆਦਿ ਤੋਂ ਵੱਡੀ ਮਾਤਰਾ ਵਿੱਚ ਡੇਟਾ ਨੂੰ ਤੇਜ਼ੀ ਨਾਲ ਅਤੇ ਕੁਸ਼ਲਤਾ ਨਾਲ ਸਕ੍ਰੈਪ ਕਰ ਸਕਦਾ ਹੈ। ਇਹ ਪ੍ਰਕਿਰਿਆ ਕਾਰੋਬਾਰਾਂ ਲਈ ਅਨਮੋਲ ਹੋ ਸਕਦੀ ਹੈ ਜਦੋਂ ਬਹੁਤ ਸਾਰੇ ਸਰੋਤਾਂ ਤੋਂ ਸੰਬੰਧਿਤ ਅਤੇ ਖਾਸ ਡੇਟਾ ਇਕੱਠਾ ਕਰਨਾ।

ਮਸ਼ੀਨ ਅਨੁਵਾਦ
ਵਿਭਿੰਨ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਟੈਕਸਟ ਦਾ ਅਨੁਵਾਦ ਕਰਨ ਲਈ ਅਨੁਸਾਰੀ ਟ੍ਰਾਂਸਕ੍ਰਿਪਸ਼ਨ ਦੇ ਨਾਲ ਜੋੜੇ ਬਣਾਏ ਗਏ ਵਿਆਪਕ ਬਹੁ-ਭਾਸ਼ਾਈ ਡੇਟਾਸੈਟਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਮਾਡਲਾਂ ਦਾ ਵਿਕਾਸ ਕਰੋ। ਇਹ ਪ੍ਰਕਿਰਿਆ ਭਾਸ਼ਾਈ ਰੁਕਾਵਟਾਂ ਨੂੰ ਦੂਰ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦੀ ਹੈ ਅਤੇ ਜਾਣਕਾਰੀ ਦੀ ਪਹੁੰਚ ਨੂੰ ਉਤਸ਼ਾਹਿਤ ਕਰਦੀ ਹੈ।
ਵਰਗੀਕਰਨ ਐਕਸਟਰੈਕਸ਼ਨ ਅਤੇ ਰਚਨਾ
ਸ਼ੈਪ ਵਰਗੀਕਰਨ ਕੱਢਣ ਅਤੇ ਸਿਰਜਣਾ ਵਿੱਚ ਮਦਦ ਕਰ ਸਕਦਾ ਹੈ। ਇਸ ਵਿੱਚ ਡੇਟਾ ਨੂੰ ਇੱਕ ਢਾਂਚਾਗਤ ਫਾਰਮੈਟ ਵਿੱਚ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨਾ ਅਤੇ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨਾ ਸ਼ਾਮਲ ਹੈ ਜੋ ਵੱਖ-ਵੱਖ ਡੇਟਾ ਪੁਆਇੰਟਾਂ ਵਿਚਕਾਰ ਸਬੰਧਾਂ ਨੂੰ ਦਰਸਾਉਂਦਾ ਹੈ। ਇਹ ਉਹਨਾਂ ਦੇ ਡੇਟਾ ਨੂੰ ਸੰਗਠਿਤ ਕਰਨ ਵਿੱਚ ਕਾਰੋਬਾਰਾਂ ਲਈ ਵਿਸ਼ੇਸ਼ ਤੌਰ 'ਤੇ ਲਾਭਦਾਇਕ ਹੋ ਸਕਦਾ ਹੈ, ਇਸ ਨੂੰ ਵਧੇਰੇ ਪਹੁੰਚਯੋਗ ਅਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ। ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਈ-ਕਾਮਰਸ ਕਾਰੋਬਾਰ ਵਿੱਚ, ਉਤਪਾਦ ਡੇਟਾ ਨੂੰ ਉਤਪਾਦ ਦੀ ਕਿਸਮ, ਬ੍ਰਾਂਡ, ਕੀਮਤ, ਆਦਿ ਦੇ ਆਧਾਰ 'ਤੇ ਸ਼੍ਰੇਣੀਬੱਧ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਗਾਹਕਾਂ ਲਈ ਉਤਪਾਦ ਕੈਟਾਲਾਗ ਨੂੰ ਨੈਵੀਗੇਟ ਕਰਨਾ ਆਸਾਨ ਹੋ ਜਾਂਦਾ ਹੈ।
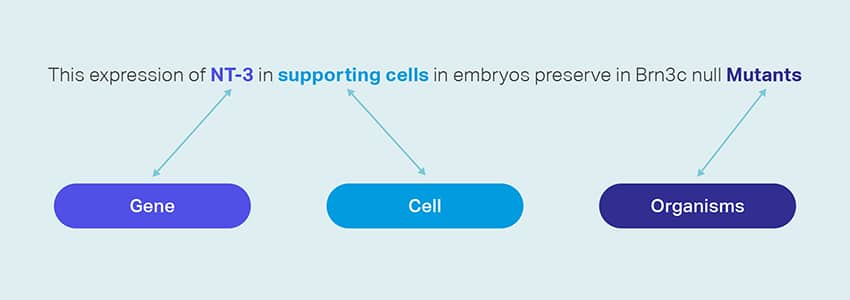
ਡਾਟਾ ਇਕੱਤਰ ਕਰਨਾ
ਸਾਡੀਆਂ ਡਾਟਾ ਇਕੱਤਰ ਕਰਨ ਵਾਲੀਆਂ ਸੇਵਾਵਾਂ ਜਨਰੇਟਿਵ AI ਐਲਗੋਰਿਦਮ ਦੀ ਸਿਖਲਾਈ ਅਤੇ ਤੁਹਾਡੇ ਮਾਡਲਾਂ ਦੀ ਸ਼ੁੱਧਤਾ ਅਤੇ ਪ੍ਰਭਾਵ ਨੂੰ ਬਿਹਤਰ ਬਣਾਉਣ ਲਈ ਜ਼ਰੂਰੀ ਅਸਲ-ਸੰਸਾਰ ਜਾਂ ਸਿੰਥੈਟਿਕ ਡੇਟਾ ਪ੍ਰਦਾਨ ਕਰਦੀਆਂ ਹਨ। ਡੇਟਾ ਗੋਪਨੀਯਤਾ ਅਤੇ ਸੁਰੱਖਿਆ ਨੂੰ ਧਿਆਨ ਵਿੱਚ ਰੱਖਦੇ ਹੋਏ ਡੇਟਾ ਨਿਰਪੱਖ, ਨੈਤਿਕ ਅਤੇ ਜ਼ਿੰਮੇਵਾਰੀ ਨਾਲ ਸਰੋਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।

ਸਵਾਲ ਅਤੇ ਜਵਾਬ
ਪ੍ਰਸ਼ਨ ਉੱਤਰ (QA) ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਪ੍ਰਕਿਰਿਆ ਦਾ ਇੱਕ ਉਪ-ਖੇਤਰ ਹੈ ਜੋ ਮਨੁੱਖੀ ਭਾਸ਼ਾ ਵਿੱਚ ਆਪਣੇ ਆਪ ਸਵਾਲਾਂ ਦੇ ਜਵਾਬ ਦੇਣ 'ਤੇ ਕੇਂਦ੍ਰਿਤ ਹੈ। QA ਪ੍ਰਣਾਲੀਆਂ ਨੂੰ ਵਿਸਤ੍ਰਿਤ ਟੈਕਸਟ ਅਤੇ ਕੋਡ 'ਤੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ, ਜਿਸ ਨਾਲ ਉਹ ਵੱਖ-ਵੱਖ ਕਿਸਮਾਂ ਦੇ ਪ੍ਰਸ਼ਨਾਂ ਨੂੰ ਸੰਭਾਲਣ ਦੇ ਯੋਗ ਬਣਾਉਂਦੇ ਹਨ, ਜਿਸ ਵਿੱਚ ਤੱਥ, ਪਰਿਭਾਸ਼ਾਤਮਕ, ਅਤੇ ਰਾਏ-ਆਧਾਰਿਤ ਸਵਾਲ ਸ਼ਾਮਲ ਹਨ। ਗਾਹਕ ਸਹਾਇਤਾ, ਸਿਹਤ ਸੰਭਾਲ, ਜਾਂ ਸਪਲਾਈ ਚੇਨ ਵਰਗੇ ਖਾਸ ਖੇਤਰਾਂ ਲਈ ਤਿਆਰ QA ਮਾਡਲਾਂ ਨੂੰ ਵਿਕਸਤ ਕਰਨ ਲਈ ਡੋਮੇਨ ਗਿਆਨ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਹਾਲਾਂਕਿ, ਜਨਰੇਟਿਵ QA ਪਹੁੰਚ ਮਾਡਲਾਂ ਨੂੰ ਸਿਰਫ਼ ਸੰਦਰਭ 'ਤੇ ਨਿਰਭਰ ਕਰਦੇ ਹੋਏ, ਡੋਮੇਨ ਗਿਆਨ ਤੋਂ ਬਿਨਾਂ ਟੈਕਸਟ ਬਣਾਉਣ ਦੀ ਇਜਾਜ਼ਤ ਦਿੰਦੇ ਹਨ।
ਮਾਹਰਾਂ ਦੀ ਸਾਡੀ ਟੀਮ ਸਵਾਲ-ਜਵਾਬ ਜੋੜੇ ਤਿਆਰ ਕਰਨ ਲਈ ਵਿਆਪਕ ਦਸਤਾਵੇਜ਼ਾਂ ਜਾਂ ਮੈਨੂਅਲਾਂ ਦਾ ਧਿਆਨ ਨਾਲ ਅਧਿਐਨ ਕਰ ਸਕਦੀ ਹੈ, ਕਾਰੋਬਾਰਾਂ ਲਈ ਜਨਰੇਟਿਵ AI ਬਣਾਉਣ ਦੀ ਸਹੂਲਤ ਦਿੰਦੀ ਹੈ। ਇਹ ਪਹੁੰਚ ਇੱਕ ਵਿਆਪਕ ਕਾਰਪਸ ਤੋਂ ਢੁਕਵੀਂ ਜਾਣਕਾਰੀ ਨੂੰ ਮਾਈਨਿੰਗ ਕਰਕੇ ਉਪਭੋਗਤਾ ਪੁੱਛਗਿੱਛਾਂ ਨਾਲ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਢੰਗ ਨਾਲ ਨਜਿੱਠ ਸਕਦੀ ਹੈ। ਸਾਡੇ ਪ੍ਰਮਾਣਿਤ ਮਾਹਰ ਉੱਚ-ਗੁਣਵੱਤਾ ਵਾਲੇ ਸਵਾਲ ਅਤੇ ਜਵਾਬ ਜੋੜਿਆਂ ਦੇ ਉਤਪਾਦਨ ਨੂੰ ਯਕੀਨੀ ਬਣਾਉਂਦੇ ਹਨ ਜੋ ਵਿਭਿੰਨ ਵਿਸ਼ਿਆਂ ਅਤੇ ਡੋਮੇਨਾਂ ਵਿੱਚ ਫੈਲਦੇ ਹਨ।

ਟੈਕਸਟ ਸੰਖੇਪ
ਸਾਡੇ ਮਾਹਰ ਵਿਆਪਕ ਸੰਵਾਦਾਂ ਜਾਂ ਲੰਬੇ ਸੰਵਾਦਾਂ ਨੂੰ ਦੂਰ ਕਰਨ ਦੇ ਸਮਰੱਥ ਹਨ, ਵਿਆਪਕ ਟੈਕਸਟ ਡੇਟਾ ਤੋਂ ਸੰਖੇਪ ਅਤੇ ਸਮਝਦਾਰ ਸਾਰਾਂਸ਼ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ।

ਟੈਕਸਟ ਜਨਰੇਸ਼ਨ
ਵਿਭਿੰਨ ਸ਼ੈਲੀਆਂ ਵਿੱਚ ਟੈਕਸਟ ਦੇ ਇੱਕ ਵਿਸ਼ਾਲ ਡੇਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਮਾਡਲਾਂ ਨੂੰ ਸਿਖਲਾਈ ਦਿਓ, ਜਿਵੇਂ ਕਿ ਖਬਰ ਲੇਖ, ਗਲਪ, ਅਤੇ ਕਵਿਤਾ। ਇਹ ਮਾਡਲ ਫਿਰ ਸਮੱਗਰੀ ਬਣਾਉਣ ਲਈ ਲਾਗਤ-ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਅਤੇ ਸਮਾਂ ਬਚਾਉਣ ਵਾਲੇ ਹੱਲ ਦੀ ਪੇਸ਼ਕਸ਼ ਕਰਦੇ ਹੋਏ ਖਬਰਾਂ ਦੇ ਟੁਕੜੇ, ਬਲੌਗ ਐਂਟਰੀਆਂ, ਜਾਂ ਸੋਸ਼ਲ ਮੀਡੀਆ ਪੋਸਟਾਂ ਸਮੇਤ ਕਈ ਕਿਸਮਾਂ ਦੀ ਸਮੱਗਰੀ ਤਿਆਰ ਕਰ ਸਕਦੇ ਹਨ।
ਸਪੀਚ ਰੇਕੋਗਨੀਸ਼ਨ
ਵੱਖ-ਵੱਖ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ ਬੋਲੀ ਜਾਣ ਵਾਲੀ ਭਾਸ਼ਾ ਨੂੰ ਸਮਝਣ ਦੇ ਸਮਰੱਥ ਮਾਡਲ ਵਿਕਸਿਤ ਕਰੋ। ਇਸ ਵਿੱਚ ਵੌਇਸ-ਐਕਟੀਵੇਟਿਡ ਸਹਾਇਕ, ਡਿਕਸ਼ਨ ਸੌਫਟਵੇਅਰ, ਅਤੇ ਰੀਅਲ-ਟਾਈਮ ਅਨੁਵਾਦ ਟੂਲ ਸ਼ਾਮਲ ਹਨ। ਇਸ ਪ੍ਰਕਿਰਿਆ ਵਿੱਚ ਬੋਲੀਆਂ ਜਾਣ ਵਾਲੀਆਂ ਭਾਸ਼ਾਵਾਂ ਦੀਆਂ ਆਡੀਓ ਰਿਕਾਰਡਿੰਗਾਂ ਵਾਲੇ ਇੱਕ ਵਿਆਪਕ ਡੇਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਨਾ ਸ਼ਾਮਲ ਹੈ, ਉਹਨਾਂ ਦੇ ਅਨੁਸਾਰੀ ਟ੍ਰਾਂਸਕ੍ਰਿਪਟਾਂ ਨਾਲ ਜੋੜਿਆ ਗਿਆ ਹੈ।

ਉਤਪਾਦ ਸਿਫਾਰਸ਼ਾਂ
ਗਾਹਕ ਖਰੀਦਣ ਦੇ ਇਤਿਹਾਸ ਦੇ ਵਿਆਪਕ ਡੇਟਾਸੈਟਾਂ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ ਮਾਡਲਾਂ ਦਾ ਵਿਕਾਸ ਕਰੋ, ਜਿਸ ਵਿੱਚ ਲੇਬਲ ਵੀ ਸ਼ਾਮਲ ਹਨ ਜੋ ਇਹ ਦਰਸਾਉਂਦੇ ਹਨ ਕਿ ਗਾਹਕ ਖਰੀਦਣ ਲਈ ਝੁਕਾਅ ਰੱਖਦੇ ਹਨ। ਟੀਚਾ ਗਾਹਕਾਂ ਨੂੰ ਸਟੀਕ ਸੁਝਾਅ ਪ੍ਰਦਾਨ ਕਰਨਾ ਹੈ, ਜਿਸ ਨਾਲ ਵਿਕਰੀ ਨੂੰ ਹੁਲਾਰਾ ਦੇਣਾ ਅਤੇ ਗਾਹਕਾਂ ਦੀ ਸੰਤੁਸ਼ਟੀ ਨੂੰ ਵਧਾਉਣਾ ਹੈ।
ਚਿੱਤਰ ਕੈਪਸ਼ਨਿੰਗ
ਸਾਡੀ ਅਤਿ-ਆਧੁਨਿਕ, AI-ਸੰਚਾਲਿਤ ਚਿੱਤਰ ਕੈਪਸ਼ਨਿੰਗ ਸੇਵਾ ਨਾਲ ਆਪਣੀ ਚਿੱਤਰ ਵਿਆਖਿਆ ਪ੍ਰਕਿਰਿਆ ਨੂੰ ਕ੍ਰਾਂਤੀਕਾਰੀ ਬਣਾਓ। ਅਸੀਂ ਸਹੀ ਅਤੇ ਪ੍ਰਸੰਗਿਕ ਤੌਰ 'ਤੇ ਅਰਥਪੂਰਣ ਵਰਣਨ ਪੈਦਾ ਕਰਕੇ ਤਸਵੀਰਾਂ ਵਿੱਚ ਜੀਵਨਸ਼ਕਤੀ ਪੈਦਾ ਕਰਦੇ ਹਾਂ। ਇਹ ਤੁਹਾਡੇ ਦਰਸ਼ਕਾਂ ਲਈ ਤੁਹਾਡੀ ਵਿਜ਼ੂਅਲ ਸਮਗਰੀ ਦੇ ਨਾਲ ਨਵੀਨਤਾਕਾਰੀ ਰੁਝੇਵਿਆਂ ਅਤੇ ਪਰਸਪਰ ਪ੍ਰਭਾਵ ਦੀਆਂ ਸੰਭਾਵਨਾਵਾਂ ਦਾ ਰਾਹ ਪੱਧਰਾ ਕਰਦਾ ਹੈ।

ਟੈਕਸਟ-ਟੂ-ਸਪੀਚ ਸੇਵਾਵਾਂ ਦੀ ਸਿਖਲਾਈ
ਅਸੀਂ ਮਨੁੱਖੀ ਸਪੀਚ ਆਡੀਓ ਰਿਕਾਰਡਿੰਗਾਂ ਦਾ ਇੱਕ ਵਿਸ਼ਾਲ ਡੇਟਾਸੈਟ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਾਂ, AI ਮਾਡਲਾਂ ਦੀ ਸਿਖਲਾਈ ਲਈ ਆਦਰਸ਼। ਇਹ ਮਾਡਲ ਤੁਹਾਡੀਆਂ ਐਪਲੀਕੇਸ਼ਨਾਂ ਲਈ ਕੁਦਰਤੀ ਅਤੇ ਆਕਰਸ਼ਕ ਆਵਾਜ਼ਾਂ ਪੈਦਾ ਕਰਨ ਦੇ ਸਮਰੱਥ ਹਨ, ਇਸ ਤਰ੍ਹਾਂ ਤੁਹਾਡੇ ਉਪਭੋਗਤਾਵਾਂ ਲਈ ਇੱਕ ਵਿਲੱਖਣ ਅਤੇ ਇਮਰਸਿਵ ਧੁਨੀ ਅਨੁਭਵ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ।



