ਇੰਟਰਨੈੱਟ ਨੇ ਲੋਕਾਂ ਲਈ ਦੁਨੀਆ ਦੀ ਕਿਸੇ ਵੀ ਚੀਜ਼ 'ਤੇ ਆਪਣੇ ਵਿਚਾਰਾਂ, ਵਿਚਾਰਾਂ ਅਤੇ ਸੁਝਾਵਾਂ ਨੂੰ ਖੁੱਲ੍ਹ ਕੇ ਪ੍ਰਗਟ ਕਰਨ ਲਈ ਦਰਵਾਜ਼ੇ ਖੋਲ੍ਹ ਦਿੱਤੇ ਹਨ। ਸਮਾਜਿਕ ਮੀਡੀਆ ਨੂੰ, ਵੈੱਬਸਾਈਟਾਂ, ਅਤੇ ਬਲੌਗ। ਆਪਣੇ ਵਿਚਾਰ ਪ੍ਰਗਟ ਕਰਨ ਤੋਂ ਇਲਾਵਾ, ਲੋਕ (ਗਾਹਕ) ਦੂਜਿਆਂ ਦੇ ਖਰੀਦਣ ਦੇ ਫੈਸਲਿਆਂ ਨੂੰ ਵੀ ਪ੍ਰਭਾਵਿਤ ਕਰ ਰਹੇ ਹਨ। ਭਾਵਨਾ, ਭਾਵੇਂ ਨਕਾਰਾਤਮਕ ਜਾਂ ਸਕਾਰਾਤਮਕ, ਕਿਸੇ ਵੀ ਕਾਰੋਬਾਰ ਜਾਂ ਬ੍ਰਾਂਡ ਲਈ ਇਸਦੇ ਉਤਪਾਦਾਂ ਜਾਂ ਸੇਵਾਵਾਂ ਦੀ ਵਿਕਰੀ ਬਾਰੇ ਚਿੰਤਤ ਹੈ।
ਕਾਰੋਬਾਰਾਂ ਦੀ ਵਪਾਰਕ ਵਰਤੋਂ ਲਈ ਟਿੱਪਣੀਆਂ ਨੂੰ ਬਣਾਉਣ ਵਿੱਚ ਮਦਦ ਕਰਨਾ ਹੈ ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਪ੍ਰੋਸੈਸਿੰਗ. ਹਰ ਚਾਰ ਕਾਰੋਬਾਰਾਂ ਵਿੱਚੋਂ ਇੱਕ ਉਨ੍ਹਾਂ ਦੇ ਵਪਾਰਕ ਫੈਸਲਿਆਂ ਨੂੰ ਸ਼ਕਤੀ ਦੇਣ ਲਈ ਅਗਲੇ ਸਾਲ ਦੇ ਅੰਦਰ NLP ਤਕਨਾਲੋਜੀ ਨੂੰ ਲਾਗੂ ਕਰਨ ਦੀ ਯੋਜਨਾ ਹੈ। ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹੋਏ, NLP ਕਾਰੋਬਾਰਾਂ ਨੂੰ ਕੱਚੇ ਅਤੇ ਗੈਰ-ਸੰਗਠਿਤ ਡੇਟਾ ਤੋਂ ਵਿਆਖਿਆਯੋਗ ਸਮਝ ਪ੍ਰਾਪਤ ਕਰਨ ਵਿੱਚ ਮਦਦ ਕਰਦਾ ਹੈ।
ਰਾਏ ਮਾਈਨਿੰਗ ਜ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ NLP ਦੀ ਇੱਕ ਤਕਨੀਕ ਹੈ ਜੋ ਸਹੀ ਭਾਵਨਾ ਦੀ ਪਛਾਣ ਕਰਨ ਲਈ ਵਰਤੀ ਜਾਂਦੀ ਹੈ - ਸਕਾਰਾਤਮਕ, ਨਕਾਰਾਤਮਕ, ਜਾਂ ਨਿਰਪੱਖ - ਟਿੱਪਣੀਆਂ ਅਤੇ ਫੀਡਬੈਕ ਨਾਲ ਸੰਬੰਧਿਤ। NLP ਦੀ ਮਦਦ ਨਾਲ, ਕੀਵਰਡ ਵਿੱਚ ਮੌਜੂਦ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਸ਼ਬਦਾਂ ਨੂੰ ਨਿਰਧਾਰਤ ਕਰਨ ਲਈ ਟਿੱਪਣੀਆਂ ਵਿੱਚ ਕੀਵਰਡਸ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਭਾਵਨਾਵਾਂ ਨੂੰ ਇੱਕ ਸਕੇਲਿੰਗ ਸਿਸਟਮ 'ਤੇ ਸਕੋਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਜੋ ਟੈਕਸਟ ਦੇ ਇੱਕ ਟੁਕੜੇ ਵਿੱਚ ਭਾਵਨਾਵਾਂ ਲਈ ਭਾਵਨਾ ਸਕੋਰ ਨਿਰਧਾਰਤ ਕਰਦਾ ਹੈ (ਪਾਠ ਨੂੰ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਵਜੋਂ ਨਿਰਧਾਰਤ ਕਰਨਾ)।
ਬਹੁਭਾਸ਼ਾਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕੀ ਹੈ?

ਹੋਣ ਦੇ ਨਾਤੇ ਨਾਮ ਸੁਝਾਅ, ਬਹੁਭਾਸ਼ੀ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਇੱਕ ਤੋਂ ਵੱਧ ਭਾਸ਼ਾਵਾਂ ਲਈ ਭਾਵਨਾ ਸਕੋਰ ਕਰਨ ਦੀ ਤਕਨੀਕ ਹੈ। ਹਾਲਾਂਕਿ, ਇਹ ਜਿੰਨਾ ਸੌਖਾ ਨਹੀਂ ਹੈ. ਸਾਡੀ ਸੰਸਕ੍ਰਿਤੀ, ਭਾਸ਼ਾ ਅਤੇ ਅਨੁਭਵ ਸਾਡੇ ਖਰੀਦਦਾਰੀ ਵਿਵਹਾਰ ਅਤੇ ਭਾਵਨਾਵਾਂ ਨੂੰ ਬਹੁਤ ਪ੍ਰਭਾਵਿਤ ਕਰਦੇ ਹਨ। ਉਪਭੋਗਤਾ ਦੀ ਭਾਸ਼ਾ, ਸੰਦਰਭ ਅਤੇ ਸੱਭਿਆਚਾਰ ਦੀ ਚੰਗੀ ਸਮਝ ਤੋਂ ਬਿਨਾਂ, ਉਪਭੋਗਤਾ ਦੇ ਇਰਾਦਿਆਂ, ਭਾਵਨਾਵਾਂ ਅਤੇ ਵਿਆਖਿਆਵਾਂ ਨੂੰ ਸਹੀ ਢੰਗ ਨਾਲ ਸਮਝਣਾ ਅਸੰਭਵ ਹੈ।
ਜਦੋਂ ਕਿ ਆਟੋਮੇਸ਼ਨ ਸਾਡੇ ਆਧੁਨਿਕ ਸਮੇਂ ਦੀਆਂ ਬਹੁਤ ਸਾਰੀਆਂ ਮੁਸੀਬਤਾਂ ਦਾ ਜਵਾਬ ਹੈ, ਮਸ਼ੀਨ ਅਨੁਵਾਦ ਸਾਫਟਵੇਅਰ ਟਿੱਪਣੀਆਂ ਵਿੱਚ ਭਾਸ਼ਾ, ਬੋਲਚਾਲ, ਸੂਖਮਤਾ, ਅਤੇ ਸੱਭਿਆਚਾਰਕ ਸੰਦਰਭਾਂ ਦੀਆਂ ਬਾਰੀਕੀਆਂ ਨੂੰ ਚੁੱਕਣ ਦੇ ਯੋਗ ਨਹੀਂ ਹੋਵੇਗਾ ਅਤੇ ਉਤਪਾਦ ਸਮੀਖਿਆ ਇਹ ਅਨੁਵਾਦ ਕਰ ਰਿਹਾ ਹੈ। ML ਟੂਲ ਤੁਹਾਨੂੰ ਅਨੁਵਾਦ ਦੇ ਸਕਦਾ ਹੈ, ਪਰ ਹੋ ਸਕਦਾ ਹੈ ਕਿ ਇਹ ਉਪਯੋਗੀ ਨਾ ਹੋਵੇ। ਇਹੀ ਕਾਰਨ ਹੈ ਕਿ ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾਤਮਕ ਵਿਸ਼ਲੇਸ਼ਣ ਦੀ ਲੋੜ ਹੈ।
ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਦੀ ਲੋੜ ਕਿਉਂ ਹੈ?
ਜ਼ਿਆਦਾਤਰ ਕਾਰੋਬਾਰ ਆਪਣੇ ਸੰਚਾਰ ਮਾਧਿਅਮ ਵਜੋਂ ਅੰਗਰੇਜ਼ੀ ਦੀ ਵਰਤੋਂ ਕਰਦੇ ਹਨ, ਪਰ ਇਹ ਦੁਨੀਆ ਭਰ ਦੇ ਜ਼ਿਆਦਾਤਰ ਖਪਤਕਾਰਾਂ ਦੁਆਰਾ ਨਹੀਂ ਵਰਤੀ ਜਾਂਦੀ।
ਐਥਨੋਲੋਗ ਦੇ ਅਨੁਸਾਰ, ਦੁਨੀਆ ਦੀ ਲਗਭਗ 13% ਆਬਾਦੀ ਅੰਗਰੇਜ਼ੀ ਬੋਲਦੀ ਹੈ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਬ੍ਰਿਟਿਸ਼ ਕੌਂਸਲ ਕਹਿੰਦੀ ਹੈ ਕਿ ਵਿਸ਼ਵ ਦੀ ਲਗਭਗ 25% ਆਬਾਦੀ ਅੰਗਰੇਜ਼ੀ ਦੀ ਚੰਗੀ ਸਮਝ ਰੱਖਦੀ ਹੈ। ਜੇਕਰ ਇਹਨਾਂ ਸੰਖਿਆਵਾਂ 'ਤੇ ਵਿਸ਼ਵਾਸ ਕੀਤਾ ਜਾਵੇ, ਤਾਂ ਖਪਤਕਾਰਾਂ ਦਾ ਇੱਕ ਵੱਡਾ ਹਿੱਸਾ ਅੰਗਰੇਜ਼ੀ ਤੋਂ ਇਲਾਵਾ ਕਿਸੇ ਹੋਰ ਭਾਸ਼ਾ ਵਿੱਚ ਇੱਕ ਦੂਜੇ ਅਤੇ ਕਾਰੋਬਾਰ ਨਾਲ ਗੱਲਬਾਤ ਕਰਦਾ ਹੈ।
ਜੇਕਰ ਕਾਰੋਬਾਰਾਂ ਦਾ ਮੁੱਖ ਉਦੇਸ਼ ਆਪਣੇ ਗ੍ਰਾਹਕ ਅਧਾਰ ਨੂੰ ਬਰਕਰਾਰ ਰੱਖਣਾ ਅਤੇ ਨਵੇਂ ਗਾਹਕਾਂ ਨੂੰ ਆਕਰਸ਼ਿਤ ਕਰਨਾ ਹੈ, ਤਾਂ ਇਸ ਨੂੰ ਉਹਨਾਂ ਦੇ ਗਾਹਕਾਂ ਦੇ ਵਿਚਾਰਾਂ ਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਮਝਣਾ ਚਾਹੀਦਾ ਹੈ ਜੋ ਉਹਨਾਂ ਵਿੱਚ ਪ੍ਰਗਟ ਕੀਤੇ ਗਏ ਹਨ. ਦੇਸੀ ਭਾਸ਼ਾ. ਹੱਥੀਂ ਹਰੇਕ ਟਿੱਪਣੀ ਦੀ ਸਮੀਖਿਆ ਕਰਨਾ ਜਾਂ ਉਹਨਾਂ ਦਾ ਅੰਗਰੇਜ਼ੀ ਵਿੱਚ ਅਨੁਵਾਦ ਕਰਨਾ ਇੱਕ ਮੁਸ਼ਕਲ ਪ੍ਰਕਿਰਿਆ ਹੈ ਜੋ ਪ੍ਰਭਾਵੀ ਨਤੀਜੇ ਨਹੀਂ ਦੇਵੇਗੀ।
ਇੱਕ ਟਿਕਾਊ ਹੱਲ ਹੈ ਬਹੁ-ਭਾਸ਼ਾਈ ਵਿਕਾਸ ਕਰਨਾ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਸਿਸਟਮ ਜੋ ਸੋਸ਼ਲ ਮੀਡੀਆ, ਫੋਰਮਾਂ, ਸਰਵੇਖਣਾਂ, ਅਤੇ ਹੋਰ ਬਹੁਤ ਕੁਝ ਵਿੱਚ ਗਾਹਕਾਂ ਦੇ ਵਿਚਾਰਾਂ, ਭਾਵਨਾਵਾਂ ਅਤੇ ਸੁਝਾਵਾਂ ਦਾ ਪਤਾ ਲਗਾਉਂਦੇ ਹਨ ਅਤੇ ਉਹਨਾਂ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਦੇ ਹਨ।
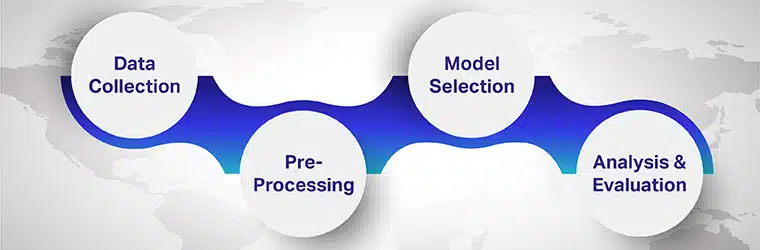
ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਨ ਲਈ ਕਦਮ
ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ, ਭਾਵੇਂ ਇੱਕ ਭਾਸ਼ਾ ਵਿੱਚ ਹੋਵੇ ਜਾਂ ਕਈ ਭਾਸ਼ਾਵਾਂ, ਇੱਕ ਪ੍ਰਕਿਰਿਆ ਹੈ ਜਿਸ ਨੂੰ ਐਕਸਟਰੈਕਟ ਕਰਨ ਲਈ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਮਾਡਲਾਂ, ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਪ੍ਰੋਸੈਸਿੰਗ, ਅਤੇ ਡੇਟਾ ਵਿਸ਼ਲੇਸ਼ਣ ਤਕਨੀਕਾਂ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ ਬਹੁਭਾਸ਼ੀ ਭਾਵਨਾ ਸਕੋਰਿੰਗ ਡਾਟਾ ਤੱਕ.
ਬਹੁਭਾਸ਼ਾਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਵਿੱਚ ਸ਼ਾਮਲ ਕਦਮ ਹਨ
ਕਦਮ 1: ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ
ਡਾਟਾ ਇਕੱਠਾ ਕਰਨਾ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਨੂੰ ਲਾਗੂ ਕਰਨ ਦਾ ਪਹਿਲਾ ਕਦਮ ਹੈ। ਇੱਕ ਬਹੁਭਾਸ਼ੀ ਬਣਾਉਣ ਲਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਮਾਡਲ, ਵੱਖ-ਵੱਖ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਡੇਟਾ ਪ੍ਰਾਪਤ ਕਰਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ। ਸਭ ਕੁਝ ਇਕੱਤਰ ਕੀਤੇ, ਐਨੋਟੇਟ ਅਤੇ ਲੇਬਲ ਕੀਤੇ ਡੇਟਾ ਦੀ ਗੁਣਵੱਤਾ 'ਤੇ ਨਿਰਭਰ ਕਰੇਗਾ। ਤੁਸੀਂ API, ਓਪਨ-ਸੋਰਸ ਰਿਪੋਜ਼ਟਰੀਆਂ, ਅਤੇ ਪ੍ਰਕਾਸ਼ਕਾਂ ਤੋਂ ਡੇਟਾ ਖਿੱਚ ਸਕਦੇ ਹੋ।
ਕਦਮ 2: ਪ੍ਰੀ-ਪ੍ਰੋਸੈਸਿੰਗ
ਇਕੱਤਰ ਕੀਤੇ ਗਏ ਵੈੱਬ ਡੇਟਾ ਨੂੰ ਸਾਫ਼ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਅਤੇ ਇਸ ਤੋਂ ਜਾਣਕਾਰੀ ਇਕੱਠੀ ਕੀਤੀ ਜਾਣੀ ਚਾਹੀਦੀ ਹੈ। ਟੈਕਸਟ ਦੇ ਉਹ ਹਿੱਸੇ ਜੋ ਕੋਈ ਖਾਸ ਅਰਥ ਨਹੀਂ ਦਿੰਦੇ, ਜਿਵੇਂ ਕਿ 'the' 'is' ਅਤੇ ਹੋਰ, ਨੂੰ ਹਟਾ ਦਿੱਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਪਾਠ ਨੂੰ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਅਰਥ ਦੱਸਣ ਲਈ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨ ਲਈ ਸ਼ਬਦਾਂ ਦੇ ਸਮੂਹਾਂ ਵਿੱਚ ਵੰਡਿਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ।
ਵਰਗੀਕਰਨ ਗੁਣਵੱਤਾ ਨੂੰ ਬਿਹਤਰ ਬਣਾਉਣ ਲਈ, ਸਮੱਗਰੀ ਨੂੰ ਸ਼ੋਰ ਤੋਂ ਸਾਫ਼ ਕੀਤਾ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ, ਜਿਵੇਂ ਕਿ HTML ਟੈਗਸ, ਇਸ਼ਤਿਹਾਰਾਂ ਅਤੇ ਸਕ੍ਰਿਪਟਾਂ। ਲੋਕਾਂ ਦੁਆਰਾ ਵਰਤੀ ਜਾਂਦੀ ਭਾਸ਼ਾ, ਕੋਸ਼, ਅਤੇ ਵਿਆਕਰਣ ਸੋਸ਼ਲ ਨੈਟਵਰਕ ਦੇ ਅਧਾਰ ਤੇ ਵੱਖਰੇ ਹੁੰਦੇ ਹਨ। ਅਜਿਹੀ ਸਮੱਗਰੀ ਨੂੰ ਆਮ ਬਣਾਉਣਾ ਅਤੇ ਇਸਨੂੰ ਪ੍ਰੀ-ਪ੍ਰੋਸੈਸਿੰਗ ਲਈ ਤਿਆਰ ਕਰਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ.
ਪ੍ਰੀ-ਪ੍ਰੋਸੈਸਿੰਗ ਵਿੱਚ ਇੱਕ ਹੋਰ ਮਹੱਤਵਪੂਰਨ ਕਦਮ ਵਾਕਾਂ ਨੂੰ ਵੰਡਣ, ਸਟਾਪ ਸ਼ਬਦਾਂ ਨੂੰ ਹਟਾਉਣ, ਭਾਸ਼ਣ ਦੇ ਭਾਗਾਂ ਨੂੰ ਟੈਗ ਕਰਨ, ਸ਼ਬਦਾਂ ਨੂੰ ਉਹਨਾਂ ਦੇ ਮੂਲ ਰੂਪ ਵਿੱਚ ਬਦਲਣ ਅਤੇ ਸ਼ਬਦਾਂ ਨੂੰ ਚਿੰਨ੍ਹ ਅਤੇ ਟੈਕਸਟ ਵਿੱਚ ਟੋਕਨਾਈਜ਼ ਕਰਨ ਲਈ ਕੁਦਰਤੀ ਭਾਸ਼ਾ ਦੀ ਪ੍ਰਕਿਰਿਆ ਦੀ ਵਰਤੋਂ ਕਰਨਾ ਹੈ।
ਕਦਮ 3: ਮਾਡਲ ਦੀ ਚੋਣ
ਨਿਯਮ-ਆਧਾਰਿਤ ਮਾਡਲ: ਬਹੁ-ਭਾਸ਼ਾਈ ਅਰਥ-ਵਿਸ਼ਲੇਸ਼ਣ ਦਾ ਸਭ ਤੋਂ ਸਰਲ ਤਰੀਕਾ ਨਿਯਮ-ਆਧਾਰਿਤ ਹੈ। ਨਿਯਮ-ਅਧਾਰਿਤ ਐਲਗੋਰਿਦਮ ਮਾਹਿਰਾਂ ਦੁਆਰਾ ਪ੍ਰੋਗਰਾਮ ਕੀਤੇ ਪੂਰਵ-ਨਿਰਧਾਰਤ ਨਿਯਮਾਂ ਦੇ ਇੱਕ ਸਮੂਹ ਦੇ ਅਧਾਰ ਤੇ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਦਾ ਹੈ।
ਨਿਯਮ ਉਹਨਾਂ ਸ਼ਬਦਾਂ ਜਾਂ ਵਾਕਾਂਸ਼ਾਂ ਨੂੰ ਨਿਸ਼ਚਿਤ ਕਰ ਸਕਦਾ ਹੈ ਜੋ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਹਨ। ਜੇਕਰ ਤੁਸੀਂ ਕਿਸੇ ਉਤਪਾਦ ਜਾਂ ਸੇਵਾ ਦੀ ਸਮੀਖਿਆ ਕਰਦੇ ਹੋ, ਉਦਾਹਰਨ ਲਈ, ਇਸ ਵਿੱਚ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਸ਼ਬਦ ਹੋ ਸਕਦੇ ਹਨ ਜਿਵੇਂ ਕਿ 'ਮਹਾਨ', 'ਹੌਲੀ', 'ਉਡੀਕ ਕਰੋ' ਅਤੇ 'ਲਾਭਦਾਇਕ'। ਇਹ ਵਿਧੀ ਸ਼ਬਦਾਂ ਦਾ ਵਰਗੀਕਰਨ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦੀ ਹੈ, ਪਰ ਇਹ ਗੁੰਝਲਦਾਰ ਜਾਂ ਘੱਟ ਵਾਰ-ਵਾਰ ਸ਼ਬਦਾਂ ਦਾ ਵਰਗੀਕਰਨ ਕਰ ਸਕਦੀ ਹੈ।
ਆਟੋਮੈਟਿਕ ਮਾਡਲ: ਆਟੋਮੈਟਿਕ ਮਾਡਲ ਮਨੁੱਖੀ ਸੰਚਾਲਕਾਂ ਦੀ ਸ਼ਮੂਲੀਅਤ ਤੋਂ ਬਿਨਾਂ ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕਰਦਾ ਹੈ। ਹਾਲਾਂਕਿ ਮਸ਼ੀਨ ਲਰਨਿੰਗ ਮਾਡਲ ਮਨੁੱਖੀ ਕੋਸ਼ਿਸ਼ਾਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਬਣਾਇਆ ਗਿਆ ਹੈ, ਇਹ ਇੱਕ ਵਾਰ ਵਿਕਸਤ ਹੋਣ 'ਤੇ ਸਹੀ ਨਤੀਜੇ ਦੇਣ ਲਈ ਆਪਣੇ ਆਪ ਕੰਮ ਕਰ ਸਕਦਾ ਹੈ।
ਟੈਸਟ ਡੇਟਾ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਕੀਤਾ ਜਾਂਦਾ ਹੈ, ਅਤੇ ਹਰੇਕ ਟਿੱਪਣੀ ਨੂੰ ਹੱਥੀਂ ਸਕਾਰਾਤਮਕ ਜਾਂ ਨਕਾਰਾਤਮਕ ਵਜੋਂ ਲੇਬਲ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ML ਮਾਡਲ ਫਿਰ ਮੌਜੂਦਾ ਟਿੱਪਣੀਆਂ ਨਾਲ ਨਵੇਂ ਟੈਕਸਟ ਦੀ ਤੁਲਨਾ ਕਰਕੇ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਕੇ ਟੈਸਟ ਡੇਟਾ ਤੋਂ ਸਿੱਖੇਗਾ।
ਕਦਮ 4: ਵਿਸ਼ਲੇਸ਼ਣ ਅਤੇ ਮੁਲਾਂਕਣ
ਨਿਯਮ-ਅਧਾਰਿਤ ਅਤੇ ਮਸ਼ੀਨ-ਲਰਨਿੰਗ ਮਾਡਲਾਂ ਨੂੰ ਸਮੇਂ ਅਤੇ ਅਨੁਭਵ ਦੇ ਨਾਲ ਸੁਧਾਰਿਆ ਅਤੇ ਵਧਾਇਆ ਜਾ ਸਕਦਾ ਹੈ। ਘੱਟ-ਵਾਰ ਵਰਤੇ ਜਾਣ ਵਾਲੇ ਸ਼ਬਦਾਂ ਜਾਂ ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾਵਾਂ ਲਈ ਲਾਈਵ ਸਕੋਰਾਂ ਦਾ ਇੱਕ ਸ਼ਬਦਕੋਸ਼ ਤੇਜ਼ ਅਤੇ ਵਧੇਰੇ ਸਹੀ ਵਰਗੀਕਰਨ ਲਈ ਅੱਪਡੇਟ ਕੀਤਾ ਜਾ ਸਕਦਾ ਹੈ।
ਅਨੁਵਾਦ ਦੀ ਚੁਣੌਤੀ
ਕੀ ਅਨੁਵਾਦ ਕਾਫ਼ੀ ਨਹੀਂ ਹੈ? ਅਸਲ ਵਿੱਚ, ਨਹੀਂ!
ਅਨੁਵਾਦ ਵਿੱਚ ਇੱਕ ਭਾਸ਼ਾ ਤੋਂ ਟੈਕਸਟ ਜਾਂ ਟੈਕਸਟ ਦੇ ਸਮੂਹਾਂ ਨੂੰ ਟ੍ਰਾਂਸਫਰ ਕਰਨਾ ਅਤੇ ਦੂਜੀ ਵਿੱਚ ਇੱਕ ਸਮਾਨ ਲੱਭਣਾ ਸ਼ਾਮਲ ਹੈ। ਹਾਲਾਂਕਿ, ਅਨੁਵਾਦ ਨਾ ਤਾਂ ਸਰਲ ਹੈ ਅਤੇ ਨਾ ਹੀ ਪ੍ਰਭਾਵਸ਼ਾਲੀ ਹੈ।
ਇਹ ਇਸ ਲਈ ਹੈ ਕਿਉਂਕਿ ਮਨੁੱਖ ਭਾਸ਼ਾ ਦੀ ਵਰਤੋਂ ਨਾ ਸਿਰਫ਼ ਆਪਣੀਆਂ ਲੋੜਾਂ ਨੂੰ ਸੰਚਾਰ ਕਰਨ ਲਈ, ਸਗੋਂ ਆਪਣੀਆਂ ਭਾਵਨਾਵਾਂ ਨੂੰ ਪ੍ਰਗਟ ਕਰਨ ਲਈ ਵੀ ਕਰਦੇ ਹਨ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਵੱਖ-ਵੱਖ ਭਾਸ਼ਾਵਾਂ, ਜਿਵੇਂ ਕਿ ਅੰਗਰੇਜ਼ੀ, ਹਿੰਦੀ, ਮੈਂਡਰਿਨ ਅਤੇ ਥਾਈ ਵਿਚ ਬਹੁਤ ਅੰਤਰ ਹਨ। ਇਸ ਸਾਹਿਤਕ ਮਿਸ਼ਰਣ ਵਿੱਚ ਭਾਵਨਾਵਾਂ, ਗਾਲਾਂ, ਮੁਹਾਵਰੇ, ਵਿਅੰਗ ਅਤੇ ਇਮੋਜੀ ਦੀ ਵਰਤੋਂ ਸ਼ਾਮਲ ਕਰੋ। ਪਾਠ ਦਾ ਸਹੀ ਅਨੁਵਾਦ ਪ੍ਰਾਪਤ ਕਰਨਾ ਸੰਭਵ ਨਹੀਂ ਹੈ।
ਦੀਆਂ ਕੁਝ ਮੁੱਖ ਚੁਣੌਤੀਆਂ ਹਨ ਮਸ਼ੀਨ ਅਨੁਵਾਦ ਹਨ
- ਵਿਸ਼ਿਸ਼ਟਤਾ
- ਪਰਸੰਗ
- ਗਾਲਾਂ ਅਤੇ ਮੁਹਾਵਰੇ
- ਸਰਕਾਮ
- ਤੁਲਨਾ
- ਨਿਰਪੱਖਤਾ
- ਇਮੋਜੀ ਅਤੇ ਸ਼ਬਦਾਂ ਦੀ ਆਧੁਨਿਕ ਵਰਤੋਂ।
ਉਹਨਾਂ ਦੇ ਉਤਪਾਦਾਂ, ਕੀਮਤਾਂ, ਸੇਵਾਵਾਂ, ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਅਤੇ ਗੁਣਵੱਤਾ ਦੇ ਸੰਬੰਧ ਵਿੱਚ ਸਮੀਖਿਆਵਾਂ, ਟਿੱਪਣੀਆਂ ਅਤੇ ਸੰਚਾਰ ਦੇ ਇਰਾਦੇ ਦੇ ਅਰਥਾਂ ਨੂੰ ਸਹੀ ਢੰਗ ਨਾਲ ਸਮਝਣ ਤੋਂ ਬਿਨਾਂ, ਕਾਰੋਬਾਰ ਗਾਹਕਾਂ ਦੀਆਂ ਲੋੜਾਂ ਅਤੇ ਵਿਚਾਰਾਂ ਨੂੰ ਸਮਝਣ ਵਿੱਚ ਅਸਮਰੱਥ ਹੋਣਗੇ।
ਬਹੁ-ਭਾਸ਼ਾਈ ਭਾਵਨਾਵਾਂ ਦਾ ਵਿਸ਼ਲੇਸ਼ਣ ਇੱਕ ਚੁਣੌਤੀਪੂਰਨ ਪ੍ਰਕਿਰਿਆ ਹੈ। ਹਰੇਕ ਭਾਸ਼ਾ ਦਾ ਆਪਣਾ ਵਿਲੱਖਣ ਸ਼ਬਦ-ਕੋਸ਼, ਵਾਕ-ਵਿਧਾਨ, ਰੂਪ ਵਿਗਿਆਨ ਅਤੇ ਧੁਨੀ ਵਿਗਿਆਨ ਹੁੰਦਾ ਹੈ। ਇਸ ਵਿੱਚ ਸੱਭਿਆਚਾਰ, ਗਾਲੀ-ਗਲੋਚ, ਭਾਵਨਾਵਾਂ ਦਾ ਪ੍ਰਗਟਾਵਾ ਕੀਤਾ, ਵਿਅੰਗ, ਅਤੇ ਧੁਨੀ, ਅਤੇ ਤੁਹਾਡੇ ਕੋਲ ਇੱਕ ਚੁਣੌਤੀਪੂਰਨ ਬੁਝਾਰਤ ਹੈ ਜਿਸਨੂੰ ਇੱਕ ਕੁਸ਼ਲ AI-ਸੰਚਾਲਿਤ ML ਹੱਲ ਦੀ ਲੋੜ ਹੈ।
ਮਜਬੂਤ ਬਹੁਭਾਸ਼ਾਈ ਨੂੰ ਵਿਕਸਤ ਕਰਨ ਲਈ ਇੱਕ ਵਿਆਪਕ ਬਹੁ-ਭਾਸ਼ਾ ਡੇਟਾਸੈਟ ਦੀ ਲੋੜ ਹੈ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਟੂਲ ਜੋ ਸਮੀਖਿਆਵਾਂ ਦੀ ਪ੍ਰਕਿਰਿਆ ਕਰ ਸਕਦਾ ਹੈ ਅਤੇ ਕਾਰੋਬਾਰਾਂ ਨੂੰ ਸ਼ਕਤੀਸ਼ਾਲੀ ਸਮਝ ਪ੍ਰਦਾਨ ਕਰ ਸਕਦਾ ਹੈ। ਸ਼ੈਪ ਕਈ ਭਾਸ਼ਾਵਾਂ ਵਿੱਚ ਉਦਯੋਗ-ਕਸਟਮਾਈਜ਼ਡ, ਲੇਬਲ ਕੀਤੇ, ਐਨੋਟੇਟਡ ਡੇਟਾਸੈਟ ਪ੍ਰਦਾਨ ਕਰਨ ਵਿੱਚ ਮਾਰਕੀਟ ਲੀਡਰ ਹੈ ਜੋ ਕੁਸ਼ਲ ਅਤੇ ਸਟੀਕ ਵਿਕਾਸ ਵਿੱਚ ਸਹਾਇਤਾ ਕਰਦੇ ਹਨ। ਬਹੁਭਾਸ਼ੀ ਭਾਵਨਾ ਵਿਸ਼ਲੇਸ਼ਣ ਹੱਲ.