
AI, Big Data, ਅਤੇ Machine Learning ਪੂਰੀ ਦੁਨੀਆ ਵਿੱਚ ਨੀਤੀ ਨਿਰਮਾਤਾਵਾਂ, ਕਾਰੋਬਾਰਾਂ, ਵਿਗਿਆਨ, ਮੀਡੀਆ ਹਾਊਸਾਂ ਅਤੇ ਕਈ ਤਰ੍ਹਾਂ ਦੇ ਉਦਯੋਗਾਂ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕਰਨਾ ਜਾਰੀ ਰੱਖਦੇ ਹਨ। ਰਿਪੋਰਟਾਂ ਸੁਝਾਅ ਦਿੰਦੀਆਂ ਹਨ ਕਿ AI ਦੀ ਗਲੋਬਲ ਗੋਦ ਲੈਣ ਦੀ ਦਰ ਇਸ ਸਮੇਂ 'ਤੇ ਹੈ 35 ਵਿੱਚ 2022% - 4 ਤੋਂ 2021% ਦਾ ਭਾਰੀ ਵਾਧਾ। ਇੱਕ ਵਾਧੂ 42% ਕੰਪਨੀਆਂ ਕਥਿਤ ਤੌਰ 'ਤੇ ਆਪਣੇ ਕਾਰੋਬਾਰ ਲਈ AI ਦੇ ਬਹੁਤ ਸਾਰੇ ਲਾਭਾਂ ਦੀ ਪੜਚੋਲ ਕਰ ਰਹੀਆਂ ਹਨ।
ਬਹੁਤ ਸਾਰੀਆਂ AI ਪਹਿਲਕਦਮੀਆਂ ਨੂੰ ਸ਼ਕਤੀ ਪ੍ਰਦਾਨ ਕਰਨਾ ਅਤੇ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਹੱਲ ਡਾਟਾ ਹੈ. AI ਸਿਰਫ ਓਨਾ ਹੀ ਵਧੀਆ ਹੋ ਸਕਦਾ ਹੈ ਜਿੰਨਾ ਡੇਟਾ ਐਲਗੋਰਿਦਮ ਨੂੰ ਫੀਡ ਕਰਦਾ ਹੈ। ਘੱਟ-ਗੁਣਵੱਤਾ ਵਾਲੇ ਡੇਟਾ ਦੇ ਨਤੀਜੇ ਵਜੋਂ ਘੱਟ-ਗੁਣਵੱਤਾ ਵਾਲੇ ਨਤੀਜੇ ਅਤੇ ਗਲਤ ਭਵਿੱਖਬਾਣੀਆਂ ਹੋ ਸਕਦੀਆਂ ਹਨ।
ਹਾਲਾਂਕਿ ML ਅਤੇ AI ਹੱਲ ਦੇ ਵਿਕਾਸ 'ਤੇ ਬਹੁਤ ਧਿਆਨ ਦਿੱਤਾ ਗਿਆ ਹੈ, ਇੱਕ ਗੁਣਵੱਤਾ ਡੇਟਾਸੈਟ ਦੇ ਤੌਰ 'ਤੇ ਕੀ ਯੋਗ ਹੈ ਇਸ ਬਾਰੇ ਜਾਗਰੂਕਤਾ ਗਾਇਬ ਹੈ। ਇਸ ਲੇਖ ਵਿੱਚ, ਅਸੀਂ ਦੀ ਟਾਈਮਲਾਈਨ ਨੂੰ ਨੈਵੀਗੇਟ ਕਰਦੇ ਹਾਂ ਗੁਣਵੱਤਾ AI ਸਿਖਲਾਈ ਡਾਟਾ ਅਤੇ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਸਿਖਲਾਈ ਦੀ ਸਮਝ ਦੁਆਰਾ AI ਦੇ ਭਵਿੱਖ ਦੀ ਪਛਾਣ ਕਰੋ।
AI ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਪਰਿਭਾਸ਼ਾ
ਇੱਕ ML ਹੱਲ ਬਣਾਉਂਦੇ ਸਮੇਂ, ਸਿਖਲਾਈ ਡੇਟਾਸੈਟ ਦੀ ਮਾਤਰਾ ਅਤੇ ਗੁਣਵੱਤਾ ਮਾਇਨੇ ਰੱਖਦੀ ਹੈ। ML ਸਿਸਟਮ ਨੂੰ ਨਾ ਸਿਰਫ਼ ਗਤੀਸ਼ੀਲ, ਨਿਰਪੱਖ, ਅਤੇ ਕੀਮਤੀ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਵੱਡੀ ਮਾਤਰਾ ਦੀ ਲੋੜ ਹੁੰਦੀ ਹੈ, ਸਗੋਂ ਇਸਦੀ ਬਹੁਤ ਜ਼ਿਆਦਾ ਲੋੜ ਹੁੰਦੀ ਹੈ।
ਪਰ ਏਆਈ ਸਿਖਲਾਈ ਡੇਟਾ ਕੀ ਹੈ?
AI ਸਿਖਲਾਈ ਡੇਟਾ ਸਹੀ ਪੂਰਵ-ਅਨੁਮਾਨਾਂ ਕਰਨ ਲਈ ML ਐਲਗੋਰਿਦਮ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣ ਲਈ ਵਰਤੇ ਗਏ ਲੇਬਲ ਕੀਤੇ ਡੇਟਾ ਦਾ ਸੰਗ੍ਰਹਿ ਹੈ। ML ਸਿਸਟਮ ਪੈਟਰਨਾਂ ਨੂੰ ਪਛਾਣਨ ਅਤੇ ਪਛਾਣਨ ਦੀ ਕੋਸ਼ਿਸ਼ ਕਰਦਾ ਹੈ, ਮਾਪਦੰਡਾਂ ਵਿਚਕਾਰ ਸਬੰਧਾਂ ਨੂੰ ਸਮਝਦਾ ਹੈ, ਲੋੜੀਂਦੇ ਫੈਸਲੇ ਲੈਂਦਾ ਹੈ, ਅਤੇ ਸਿਖਲਾਈ ਡੇਟਾ ਦੇ ਆਧਾਰ 'ਤੇ ਮੁਲਾਂਕਣ ਕਰਦਾ ਹੈ।
ਉਦਾਹਰਨ ਲਈ, ਸਵੈ-ਡਰਾਈਵਿੰਗ ਕਾਰਾਂ ਦੀ ਉਦਾਹਰਣ ਲਓ। ਸਵੈ-ਡਰਾਈਵਿੰਗ ML ਮਾਡਲ ਲਈ ਸਿਖਲਾਈ ਡੇਟਾਸੈਟ ਵਿੱਚ ਕਾਰਾਂ, ਪੈਦਲ ਚੱਲਣ ਵਾਲਿਆਂ, ਸੜਕ ਦੇ ਚਿੰਨ੍ਹ ਅਤੇ ਹੋਰ ਵਾਹਨਾਂ ਦੇ ਲੇਬਲ ਕੀਤੇ ਚਿੱਤਰ ਅਤੇ ਵੀਡੀਓ ਸ਼ਾਮਲ ਹੋਣੇ ਚਾਹੀਦੇ ਹਨ।
ਸੰਖੇਪ ਵਿੱਚ, ML ਐਲਗੋਰਿਦਮ ਦੀ ਗੁਣਵੱਤਾ ਨੂੰ ਵਧਾਉਣ ਲਈ, ਤੁਹਾਨੂੰ ਚੰਗੀ ਤਰ੍ਹਾਂ ਸਟ੍ਰਕਚਰਡ, ਐਨੋਟੇਟਿਡ, ਅਤੇ ਲੇਬਲ ਕੀਤੇ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਵੱਡੀ ਮਾਤਰਾ ਦੀ ਲੋੜ ਹੈ।
ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਅਤੇ ਇਸਦੇ ਵਿਕਾਸ ਦੀ ਮਹੱਤਤਾ
ਉੱਚ-ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ AI ਅਤੇ ML ਐਪ ਵਿਕਾਸ ਵਿੱਚ ਮੁੱਖ ਇਨਪੁਟ ਹੈ। ਵੱਖ-ਵੱਖ ਸਰੋਤਾਂ ਤੋਂ ਡਾਟਾ ਇਕੱਠਾ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਅਤੇ ਮਸ਼ੀਨ ਸਿਖਲਾਈ ਦੇ ਉਦੇਸ਼ਾਂ ਲਈ ਅਸੰਗਠਿਤ ਰੂਪ ਵਿੱਚ ਪੇਸ਼ ਕੀਤਾ ਜਾਂਦਾ ਹੈ। ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ - ਲੇਬਲ ਕੀਤਾ, ਐਨੋਟੇਟ ਕੀਤਾ, ਅਤੇ ਟੈਗ ਕੀਤਾ - ਹਮੇਸ਼ਾ ਇੱਕ ਸੰਗਠਿਤ ਫਾਰਮੈਟ ਵਿੱਚ ਹੁੰਦਾ ਹੈ - ML ਸਿਖਲਾਈ ਲਈ ਆਦਰਸ਼।
ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ML ਸਿਸਟਮ ਲਈ ਵਸਤੂਆਂ ਦੀ ਪਛਾਣ ਕਰਨਾ ਅਤੇ ਉਹਨਾਂ ਨੂੰ ਪੂਰਵ-ਨਿਰਧਾਰਤ ਵਿਸ਼ੇਸ਼ਤਾਵਾਂ ਦੇ ਅਨੁਸਾਰ ਸ਼੍ਰੇਣੀਬੱਧ ਕਰਨਾ ਆਸਾਨ ਬਣਾਉਂਦਾ ਹੈ। ਜੇਕਰ ਵਰਗੀਕਰਨ ਸਹੀ ਨਹੀਂ ਹੈ ਤਾਂ ਡੇਟਾਸੈਟ ਮਾੜੇ ਮਾਡਲ ਨਤੀਜੇ ਦੇ ਸਕਦਾ ਹੈ।
ਏਆਈ ਸਿਖਲਾਈ ਡੇਟਾ ਦੇ ਸ਼ੁਰੂਆਤੀ ਦਿਨ
ਮੌਜੂਦਾ ਕਾਰੋਬਾਰ ਅਤੇ ਖੋਜ ਸੰਸਾਰ ਵਿੱਚ ਏਆਈ ਦਾ ਦਬਦਬਾ ਹੋਣ ਦੇ ਬਾਵਜੂਦ, ML ਦੇ ਦਬਦਬੇ ਤੋਂ ਪਹਿਲਾਂ ਦੇ ਸ਼ੁਰੂਆਤੀ ਦਿਨਾਂ ਵਿੱਚ ਬਣਾਵਟੀ ਗਿਆਨ ਕਾਫ਼ੀ ਵੱਖਰਾ ਸੀ।
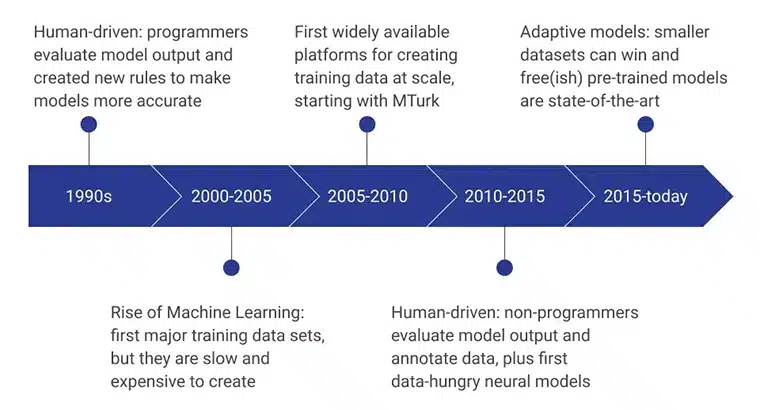
AI ਸਿਖਲਾਈ ਡੇਟਾ ਦੇ ਸ਼ੁਰੂਆਤੀ ਪੜਾਅ ਮਨੁੱਖੀ ਪ੍ਰੋਗਰਾਮਰਾਂ ਦੁਆਰਾ ਸੰਚਾਲਿਤ ਕੀਤੇ ਗਏ ਸਨ ਜਿਨ੍ਹਾਂ ਨੇ ਮਾਡਲ ਨੂੰ ਵਧੇਰੇ ਕੁਸ਼ਲ ਬਣਾਉਣ ਵਾਲੇ ਨਵੇਂ ਨਿਯਮਾਂ ਨੂੰ ਲਗਾਤਾਰ ਤਿਆਰ ਕਰਕੇ ਮਾਡਲ ਆਉਟਪੁੱਟ ਦਾ ਮੁਲਾਂਕਣ ਕੀਤਾ। 2000 - 2005 ਦੀ ਮਿਆਦ ਵਿੱਚ, ਪਹਿਲਾ ਵੱਡਾ ਡੇਟਾਸੈਟ ਬਣਾਇਆ ਗਿਆ ਸੀ, ਅਤੇ ਇਹ ਇੱਕ ਬਹੁਤ ਹੀ ਹੌਲੀ, ਸਰੋਤ-ਨਿਰਭਰ, ਅਤੇ ਮਹਿੰਗੀ ਪ੍ਰਕਿਰਿਆ ਸੀ। ਇਸਨੇ ਸਿਖਲਾਈ ਡੇਟਾਸੈਟਾਂ ਨੂੰ ਪੈਮਾਨੇ 'ਤੇ ਵਿਕਸਤ ਕਰਨ ਦੀ ਅਗਵਾਈ ਕੀਤੀ, ਅਤੇ ਐਮਾਜ਼ਾਨ ਦੇ ਐਮਟੁਰਕ ਨੇ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਪ੍ਰਤੀ ਲੋਕਾਂ ਦੀਆਂ ਧਾਰਨਾਵਾਂ ਨੂੰ ਬਦਲਣ ਵਿੱਚ ਮਹੱਤਵਪੂਰਣ ਭੂਮਿਕਾ ਨਿਭਾਈ। ਇਸ ਦੇ ਨਾਲ ਹੀ ਮਨੁੱਖੀ ਲੇਬਲਿੰਗ ਅਤੇ ਐਨੋਟੇਸ਼ਨ ਵੀ ਸ਼ੁਰੂ ਹੋ ਗਈ।
ਅਗਲੇ ਕੁਝ ਸਾਲਾਂ ਵਿੱਚ ਡਾਟਾ ਮਾਡਲਾਂ ਨੂੰ ਬਣਾਉਣ ਅਤੇ ਮੁਲਾਂਕਣ ਕਰਨ ਵਾਲੇ ਗੈਰ-ਪ੍ਰੋਗਰਾਮਰਾਂ 'ਤੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕੀਤਾ ਗਿਆ। ਵਰਤਮਾਨ ਵਿੱਚ, ਉੱਨਤ ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਠਾ ਕਰਨ ਦੇ ਤਰੀਕਿਆਂ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਵਿਕਸਿਤ ਕੀਤੇ ਗਏ ਪ੍ਰੀ-ਟ੍ਰੇਂਡ ਮਾਡਲਾਂ 'ਤੇ ਫੋਕਸ ਹੈ।
ਗੁਣਵੱਤਾ ਵੱਧ ਮਾਤਰਾ
ਦਿਨ ਵਿੱਚ AI ਸਿਖਲਾਈ ਡੇਟਾਸੈਟਾਂ ਦੀ ਇਕਸਾਰਤਾ ਦਾ ਮੁਲਾਂਕਣ ਕਰਦੇ ਸਮੇਂ, ਡੇਟਾ ਵਿਗਿਆਨੀਆਂ ਨੇ ਧਿਆਨ ਕੇਂਦਰਿਤ ਕੀਤਾ AI ਸਿਖਲਾਈ ਡਾਟਾ ਮਾਤਰਾ ਵੱਧ ਗੁਣਵੱਤਾ.
ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਆਮ ਗਲਤ ਧਾਰਨਾ ਸੀ ਕਿ ਵੱਡੇ ਡੇਟਾਬੇਸ ਸਹੀ ਨਤੀਜੇ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ। ਡੇਟਾ ਦੀ ਪੂਰੀ ਮਾਤਰਾ ਨੂੰ ਡੇਟਾ ਦੇ ਮੁੱਲ ਦਾ ਇੱਕ ਚੰਗਾ ਸੂਚਕ ਮੰਨਿਆ ਜਾਂਦਾ ਸੀ। ਮਾਤਰਾ ਡੇਟਾਸੈਟ ਦੇ ਮੁੱਲ ਨੂੰ ਨਿਰਧਾਰਤ ਕਰਨ ਵਾਲੇ ਪ੍ਰਾਇਮਰੀ ਕਾਰਕਾਂ ਵਿੱਚੋਂ ਇੱਕ ਹੈ - ਡੇਟਾ ਗੁਣਵੱਤਾ ਦੀ ਭੂਮਿਕਾ ਨੂੰ ਮਾਨਤਾ ਦਿੱਤੀ ਗਈ ਸੀ।
ਜਾਗਰੂਕਤਾ ਜੋ ਕਿ ਡਾਟਾ ਗੁਣ ਡਾਟਾ ਸੰਪੂਰਨਤਾ, ਭਰੋਸੇਯੋਗਤਾ, ਵੈਧਤਾ, ਉਪਲਬਧਤਾ, ਅਤੇ ਸਮਾਂਬੱਧਤਾ 'ਤੇ ਨਿਰਭਰ ਕਰਦਾ ਹੈ। ਸਭ ਤੋਂ ਮਹੱਤਵਪੂਰਨ, ਪ੍ਰੋਜੈਕਟ ਲਈ ਡੇਟਾ ਅਨੁਕੂਲਤਾ ਨੇ ਇਕੱਤਰ ਕੀਤੇ ਡੇਟਾ ਦੀ ਗੁਣਵੱਤਾ ਨਿਰਧਾਰਤ ਕੀਤੀ।
ਮਾੜੇ ਸਿਖਲਾਈ ਡੇਟਾ ਦੇ ਕਾਰਨ ਸ਼ੁਰੂਆਤੀ AI ਪ੍ਰਣਾਲੀਆਂ ਦੀਆਂ ਸੀਮਾਵਾਂ
ਮਾੜਾ ਸਿਖਲਾਈ ਡੇਟਾ, ਤਕਨੀਕੀ ਕੰਪਿਊਟਿੰਗ ਪ੍ਰਣਾਲੀਆਂ ਦੀ ਘਾਟ ਦੇ ਨਾਲ, ਸ਼ੁਰੂਆਤੀ AI ਪ੍ਰਣਾਲੀਆਂ ਦੇ ਕਈ ਅਧੂਰੇ ਵਾਅਦਿਆਂ ਦਾ ਇੱਕ ਕਾਰਨ ਸੀ।
ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਘਾਟ ਕਾਰਨ, ML ਹੱਲ ਨਿਊਰਲ ਖੋਜ ਦੇ ਵਿਕਾਸ ਨੂੰ ਰੋਕਣ ਵਾਲੇ ਵਿਜ਼ੂਅਲ ਪੈਟਰਨਾਂ ਦੀ ਸਹੀ ਪਛਾਣ ਨਹੀਂ ਕਰ ਸਕੇ। ਹਾਲਾਂਕਿ ਬਹੁਤ ਸਾਰੇ ਖੋਜਕਰਤਾਵਾਂ ਨੇ ਬੋਲੀ ਜਾਣ ਵਾਲੀ ਭਾਸ਼ਾ ਦੀ ਮਾਨਤਾ ਦੇ ਵਾਅਦੇ ਦੀ ਪਛਾਣ ਕੀਤੀ ਹੈ, ਬੋਲੀ ਦੀ ਪਛਾਣ ਕਰਨ ਵਾਲੇ ਸਾਧਨਾਂ ਦੀ ਖੋਜ ਜਾਂ ਵਿਕਾਸ ਭਾਸ਼ਣ ਡੇਟਾਸੈਟਾਂ ਦੀ ਘਾਟ ਕਾਰਨ ਪੂਰਾ ਨਹੀਂ ਹੋ ਸਕਿਆ। ਉੱਚ-ਅੰਤ ਦੇ AI ਟੂਲਸ ਨੂੰ ਵਿਕਸਤ ਕਰਨ ਵਿੱਚ ਇੱਕ ਹੋਰ ਵੱਡੀ ਰੁਕਾਵਟ ਕੰਪਿਊਟਰਾਂ ਦੀ ਗਣਨਾਤਮਕ ਅਤੇ ਸਟੋਰੇਜ ਸਮਰੱਥਾਵਾਂ ਦੀ ਘਾਟ ਸੀ।
ਕੁਆਲਿਟੀ ਟਰੇਨਿੰਗ ਡੇਟਾ ਵਿੱਚ ਸ਼ਿਫਟ
ਇਸ ਜਾਗਰੂਕਤਾ ਵਿੱਚ ਇੱਕ ਸਪਸ਼ਟ ਤਬਦੀਲੀ ਆਈ ਹੈ ਕਿ ਡੇਟਾਸੈਟ ਦੀ ਗੁਣਵੱਤਾ ਮਹੱਤਵਪੂਰਨ ਹੈ। ML ਸਿਸਟਮ ਲਈ ਮਨੁੱਖੀ ਬੁੱਧੀ ਅਤੇ ਫੈਸਲੇ ਲੈਣ ਦੀਆਂ ਸਮਰੱਥਾਵਾਂ ਦੀ ਸਹੀ ਨਕਲ ਕਰਨ ਲਈ, ਇਸ ਨੂੰ ਉੱਚ-ਆਵਾਜ਼, ਉੱਚ-ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ 'ਤੇ ਪ੍ਰਫੁੱਲਤ ਕਰਨਾ ਪੈਂਦਾ ਹੈ।
ਆਪਣੇ ML ਡੇਟਾ ਨੂੰ ਇੱਕ ਸਰਵੇਖਣ ਵਜੋਂ ਸੋਚੋ - ਜਿੰਨਾ ਵੱਡਾ ਡਾਟਾ ਨਮੂਨਾ ਆਕਾਰ, ਬਿਹਤਰ ਭਵਿੱਖਬਾਣੀ। ਜੇਕਰ ਨਮੂਨਾ ਡੇਟਾ ਵਿੱਚ ਸਾਰੇ ਵੇਰੀਏਬਲ ਸ਼ਾਮਲ ਨਹੀਂ ਹਨ, ਤਾਂ ਇਹ ਪੈਟਰਨਾਂ ਦੀ ਪਛਾਣ ਨਹੀਂ ਕਰ ਸਕਦਾ ਜਾਂ ਗਲਤ ਸਿੱਟੇ ਨਹੀਂ ਲਿਆ ਸਕਦਾ।
AI ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਤਰੱਕੀ ਅਤੇ ਬਿਹਤਰ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਲੋੜ
 AI ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਤਰੱਕੀ ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਲੋੜ ਨੂੰ ਵਧਾ ਰਹੀ ਹੈ।
AI ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਤਰੱਕੀ ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਲੋੜ ਨੂੰ ਵਧਾ ਰਹੀ ਹੈ।ਇਹ ਸਮਝ ਕਿ ਬਿਹਤਰ ਸਿਖਲਾਈ ਡੇਟਾ ਭਰੋਸੇਮੰਦ ML ਮਾਡਲਾਂ ਦੀ ਸੰਭਾਵਨਾ ਨੂੰ ਵਧਾਉਂਦਾ ਹੈ, ਨੇ ਬਿਹਤਰ ਡੇਟਾ ਸੰਗ੍ਰਹਿ, ਐਨੋਟੇਸ਼ਨ, ਅਤੇ ਲੇਬਲਿੰਗ ਵਿਧੀਆਂ ਨੂੰ ਜਨਮ ਦਿੱਤਾ। ਡੇਟਾ ਦੀ ਗੁਣਵੱਤਾ ਅਤੇ ਪ੍ਰਸੰਗਿਕਤਾ ਨੇ ਸਿੱਧੇ ਤੌਰ 'ਤੇ AI ਮਾਡਲ ਦੀ ਗੁਣਵੱਤਾ ਨੂੰ ਪ੍ਰਭਾਵਿਤ ਕੀਤਾ।
 AI ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਤਰੱਕੀ ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਲੋੜ ਨੂੰ ਵਧਾ ਰਹੀ ਹੈ।
AI ਤਕਨਾਲੋਜੀ ਵਿੱਚ ਤਰੱਕੀ ਗੁਣਵੱਤਾ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਲੋੜ ਨੂੰ ਵਧਾ ਰਹੀ ਹੈ।ਡਾਟਾ ਗੁਣਵੱਤਾ ਅਤੇ ਸ਼ੁੱਧਤਾ 'ਤੇ ਫੋਕਸ ਵਧਾਇਆ ਗਿਆ ਹੈ
ML ਮਾਡਲ ਲਈ ਸਹੀ ਨਤੀਜੇ ਪ੍ਰਦਾਨ ਕਰਨਾ ਸ਼ੁਰੂ ਕਰਨ ਲਈ, ਇਸ ਨੂੰ ਗੁਣਵੱਤਾ ਵਾਲੇ ਡੇਟਾਸੇਟਾਂ 'ਤੇ ਖੁਆਇਆ ਜਾਂਦਾ ਹੈ ਜੋ ਦੁਹਰਾਉਣ ਵਾਲੇ ਡੇਟਾ ਰਿਫਾਈਨਿੰਗ ਕਦਮਾਂ ਵਿੱਚੋਂ ਲੰਘਦੇ ਹਨ।
ਉਦਾਹਰਨ ਲਈ, ਇੱਕ ਮਨੁੱਖ ਕੁੱਤੇ ਦੀ ਇੱਕ ਖਾਸ ਨਸਲ ਨੂੰ ਕੁੱਤੇ ਨਾਲ ਜਾਣ-ਪਛਾਣ ਦੇ ਕੁਝ ਦਿਨਾਂ ਦੇ ਅੰਦਰ-ਅੰਦਰ ਤਸਵੀਰਾਂ, ਵੀਡੀਓ, ਜਾਂ ਵਿਅਕਤੀਗਤ ਰੂਪ ਵਿੱਚ ਪਛਾਣਨ ਦੇ ਯੋਗ ਹੋ ਸਕਦਾ ਹੈ। ਲੋੜ ਪੈਣ 'ਤੇ ਇਸ ਗਿਆਨ ਨੂੰ ਯਾਦ ਕਰਨ ਅਤੇ ਖਿੱਚਣ ਲਈ ਮਨੁੱਖ ਆਪਣੇ ਅਨੁਭਵ ਅਤੇ ਸੰਬੰਧਿਤ ਜਾਣਕਾਰੀ ਤੋਂ ਖਿੱਚਦਾ ਹੈ। ਫਿਰ ਵੀ, ਇਹ ਮਸ਼ੀਨ ਲਈ ਆਸਾਨੀ ਨਾਲ ਕੰਮ ਨਹੀਂ ਕਰਦਾ. ਮਸ਼ੀਨ ਨੂੰ ਸਪਸ਼ਟ ਤੌਰ 'ਤੇ ਐਨੋਟੇਟ ਕੀਤੇ ਅਤੇ ਲੇਬਲ ਕੀਤੇ ਚਿੱਤਰਾਂ ਨਾਲ ਖੁਆਇਆ ਜਾਣਾ ਚਾਹੀਦਾ ਹੈ - ਸੈਂਕੜੇ ਜਾਂ ਹਜ਼ਾਰਾਂ - ਉਸ ਖਾਸ ਨਸਲ ਅਤੇ ਹੋਰ ਨਸਲਾਂ ਦੇ ਨਾਲ ਕੁਨੈਕਸ਼ਨ ਬਣਾਉਣ ਲਈ।
ਇੱਕ ਏਆਈ ਮਾਡਲ ਵਿੱਚ ਪੇਸ਼ ਕੀਤੀ ਗਈ ਜਾਣਕਾਰੀ ਦੇ ਨਾਲ ਸਿਖਲਾਈ ਪ੍ਰਾਪਤ ਜਾਣਕਾਰੀ ਨੂੰ ਜੋੜ ਕੇ ਨਤੀਜਿਆਂ ਦੀ ਭਵਿੱਖਬਾਣੀ ਕਰਦਾ ਹੈ ਅਸਲ ਸੰਸਾਰ. ਐਲਗੋਰਿਦਮ ਨੂੰ ਬੇਕਾਰ ਰੈਂਡਰ ਕੀਤਾ ਜਾਂਦਾ ਹੈ ਜੇਕਰ ਸਿਖਲਾਈ ਡੇਟਾ ਵਿੱਚ ਸੰਬੰਧਿਤ ਜਾਣਕਾਰੀ ਸ਼ਾਮਲ ਨਹੀਂ ਹੁੰਦੀ ਹੈ।
ਵਿਭਿੰਨ ਅਤੇ ਪ੍ਰਤੀਨਿਧ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਮਹੱਤਤਾ
ਵਧੀ ਹੋਈ ਡੇਟਾ ਵਿਭਿੰਨਤਾ ਯੋਗਤਾ ਨੂੰ ਵੀ ਵਧਾਉਂਦੀ ਹੈ, ਪੱਖਪਾਤ ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ, ਅਤੇ ਸਾਰੇ ਦ੍ਰਿਸ਼ਾਂ ਦੀ ਬਰਾਬਰ ਪ੍ਰਤੀਨਿਧਤਾ ਨੂੰ ਵਧਾਉਂਦੀ ਹੈ। ਜੇਕਰ ਏਆਈ ਮਾਡਲ ਨੂੰ ਇੱਕ ਸਮਾਨ ਡੇਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਨਿਸ਼ਚਤ ਹੋ ਸਕਦੇ ਹੋ ਕਿ ਨਵੀਂ ਐਪਲੀਕੇਸ਼ਨ ਸਿਰਫ਼ ਇੱਕ ਖਾਸ ਉਦੇਸ਼ ਲਈ ਕੰਮ ਕਰੇਗੀ ਅਤੇ ਇੱਕ ਖਾਸ ਆਬਾਦੀ ਦੀ ਸੇਵਾ ਕਰੇਗੀ।ਇੱਕ ਡੇਟਾਸੈਟ ਇੱਕ ਖਾਸ ਆਬਾਦੀ, ਨਸਲ, ਲਿੰਗ, ਚੋਣ, ਅਤੇ ਬੌਧਿਕ ਵਿਚਾਰਾਂ ਪ੍ਰਤੀ ਪੱਖਪਾਤੀ ਹੋ ਸਕਦਾ ਹੈ, ਜਿਸ ਨਾਲ ਇੱਕ ਗਲਤ ਮਾਡਲ ਹੋ ਸਕਦਾ ਹੈ।
ਇਹ ਯਕੀਨੀ ਬਣਾਉਣਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿ ਸਾਰਾ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਦੀ ਪ੍ਰਕਿਰਿਆ ਦਾ ਪ੍ਰਵਾਹ, ਜਿਸ ਵਿੱਚ ਵਿਸ਼ਾ ਪੂਲ ਦੀ ਚੋਣ, ਕਿਊਰੇਸ਼ਨ, ਐਨੋਟੇਸ਼ਨ ਅਤੇ ਲੇਬਲਿੰਗ ਸ਼ਾਮਲ ਹੈ, ਕਾਫ਼ੀ ਵਿਭਿੰਨ, ਸੰਤੁਲਿਤ ਅਤੇ ਆਬਾਦੀ ਦਾ ਪ੍ਰਤੀਨਿਧ ਹੈ।
 ਵਧੀ ਹੋਈ ਡੇਟਾ ਵਿਭਿੰਨਤਾ ਯੋਗਤਾ ਨੂੰ ਵੀ ਵਧਾਉਂਦੀ ਹੈ, ਪੱਖਪਾਤ ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ, ਅਤੇ ਸਾਰੇ ਦ੍ਰਿਸ਼ਾਂ ਦੀ ਬਰਾਬਰ ਪ੍ਰਤੀਨਿਧਤਾ ਨੂੰ ਵਧਾਉਂਦੀ ਹੈ। ਜੇਕਰ ਏਆਈ ਮਾਡਲ ਨੂੰ ਇੱਕ ਸਮਾਨ ਡੇਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਨਿਸ਼ਚਤ ਹੋ ਸਕਦੇ ਹੋ ਕਿ ਨਵੀਂ ਐਪਲੀਕੇਸ਼ਨ ਸਿਰਫ਼ ਇੱਕ ਖਾਸ ਉਦੇਸ਼ ਲਈ ਕੰਮ ਕਰੇਗੀ ਅਤੇ ਇੱਕ ਖਾਸ ਆਬਾਦੀ ਦੀ ਸੇਵਾ ਕਰੇਗੀ।
ਵਧੀ ਹੋਈ ਡੇਟਾ ਵਿਭਿੰਨਤਾ ਯੋਗਤਾ ਨੂੰ ਵੀ ਵਧਾਉਂਦੀ ਹੈ, ਪੱਖਪਾਤ ਨੂੰ ਘਟਾਉਂਦੀ ਹੈ, ਅਤੇ ਸਾਰੇ ਦ੍ਰਿਸ਼ਾਂ ਦੀ ਬਰਾਬਰ ਪ੍ਰਤੀਨਿਧਤਾ ਨੂੰ ਵਧਾਉਂਦੀ ਹੈ। ਜੇਕਰ ਏਆਈ ਮਾਡਲ ਨੂੰ ਇੱਕ ਸਮਾਨ ਡੇਟਾਸੈਟ ਦੀ ਵਰਤੋਂ ਕਰਕੇ ਸਿਖਲਾਈ ਦਿੱਤੀ ਜਾਂਦੀ ਹੈ, ਤਾਂ ਤੁਸੀਂ ਨਿਸ਼ਚਤ ਹੋ ਸਕਦੇ ਹੋ ਕਿ ਨਵੀਂ ਐਪਲੀਕੇਸ਼ਨ ਸਿਰਫ਼ ਇੱਕ ਖਾਸ ਉਦੇਸ਼ ਲਈ ਕੰਮ ਕਰੇਗੀ ਅਤੇ ਇੱਕ ਖਾਸ ਆਬਾਦੀ ਦੀ ਸੇਵਾ ਕਰੇਗੀ।ਏਆਈ ਸਿਖਲਾਈ ਡੇਟਾ ਦਾ ਭਵਿੱਖ
AI ਮਾਡਲਾਂ ਦੀ ਭਵਿੱਖੀ ਸਫਲਤਾ ML ਐਲਗੋਰਿਦਮ ਨੂੰ ਸਿਖਲਾਈ ਦੇਣ ਲਈ ਵਰਤੇ ਗਏ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਗੁਣਵੱਤਾ ਅਤੇ ਮਾਤਰਾ 'ਤੇ ਨਿਰਭਰ ਕਰਦੀ ਹੈ। ਇਹ ਪਛਾਣਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਕਿ ਡੇਟਾ ਗੁਣਵੱਤਾ ਅਤੇ ਮਾਤਰਾ ਵਿਚਕਾਰ ਇਹ ਸਬੰਧ ਕਾਰਜ-ਵਿਸ਼ੇਸ਼ ਹੈ ਅਤੇ ਇਸਦਾ ਕੋਈ ਨਿਸ਼ਚਿਤ ਜਵਾਬ ਨਹੀਂ ਹੈ।
ਅੰਤ ਵਿੱਚ, ਇੱਕ ਸਿਖਲਾਈ ਡੇਟਾ ਸੈੱਟ ਦੀ ਯੋਗਤਾ ਨੂੰ ਇਸ ਦੁਆਰਾ ਬਣਾਏ ਗਏ ਉਦੇਸ਼ ਲਈ ਭਰੋਸੇਯੋਗਤਾ ਨਾਲ ਵਧੀਆ ਪ੍ਰਦਰਸ਼ਨ ਕਰਨ ਦੀ ਯੋਗਤਾ ਦੁਆਰਾ ਪਰਿਭਾਸ਼ਿਤ ਕੀਤਾ ਜਾਂਦਾ ਹੈ।
ਡਾਟਾ ਇਕੱਤਰ ਕਰਨ ਅਤੇ ਐਨੋਟੇਸ਼ਨ ਤਕਨੀਕਾਂ ਵਿੱਚ ਤਰੱਕੀ
ਕਿਉਂਕਿ ਐੱਮ.ਐੱਲ. ਫੈੱਡ ਡੇਟਾ ਪ੍ਰਤੀ ਸੰਵੇਦਨਸ਼ੀਲ ਹੈ, ਇਸ ਲਈ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਅਤੇ ਐਨੋਟੇਸ਼ਨ ਨੀਤੀਆਂ ਨੂੰ ਸੁਚਾਰੂ ਬਣਾਉਣ ਲਈ ਇਹ ਜ਼ਰੂਰੀ ਹੈ। ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ, ਕਿਊਰੇਸ਼ਨ, ਗਲਤ ਪੇਸ਼ਕਾਰੀ, ਅਧੂਰੇ ਮਾਪ, ਗਲਤ ਸਮੱਗਰੀ, ਡਾਟਾ ਡੁਪਲੀਕੇਸ਼ਨ, ਅਤੇ ਗਲਤ ਮਾਪਾਂ ਵਿੱਚ ਗਲਤੀਆਂ ਨਾਕਾਫ਼ੀ ਡਾਟਾ ਗੁਣਵੱਤਾ ਵਿੱਚ ਯੋਗਦਾਨ ਪਾਉਂਦੀਆਂ ਹਨ।
ਡੇਟਾ ਮਾਈਨਿੰਗ, ਵੈਬ ਸਕ੍ਰੈਪਿੰਗ, ਅਤੇ ਡੇਟਾ ਐਕਸਟਰੈਕਸ਼ਨ ਦੁਆਰਾ ਸਵੈਚਲਿਤ ਡੇਟਾ ਇਕੱਠਾ ਕਰਨਾ ਤੇਜ਼ੀ ਨਾਲ ਡੇਟਾ ਉਤਪਾਦਨ ਲਈ ਰਾਹ ਪੱਧਰਾ ਕਰ ਰਿਹਾ ਹੈ। ਇਸ ਤੋਂ ਇਲਾਵਾ, ਪੂਰਵ-ਪੈਕ ਕੀਤੇ ਡੇਟਾਸੇਟ ਇੱਕ ਤੇਜ਼-ਫਿਕਸ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਦੀ ਤਕਨੀਕ ਵਜੋਂ ਕੰਮ ਕਰਦੇ ਹਨ।
ਕ੍ਰਾਊਡਸੋਰਸਿੰਗ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਦਾ ਇੱਕ ਹੋਰ ਮਾਰਗਦਰਸ਼ਕ ਤਰੀਕਾ ਹੈ। ਹਾਲਾਂਕਿ ਡੇਟਾ ਦੀ ਸੱਚਾਈ ਦੀ ਪੁਸ਼ਟੀ ਨਹੀਂ ਕੀਤੀ ਜਾ ਸਕਦੀ, ਇਹ ਜਨਤਕ ਚਿੱਤਰ ਨੂੰ ਇਕੱਠਾ ਕਰਨ ਲਈ ਇੱਕ ਵਧੀਆ ਸਾਧਨ ਹੈ। ਅੰਤ ਵਿੱਚ, ਵਿਸ਼ੇਸ਼ ਡਾਟਾ ਇਕੱਠਾ ਕਰਨ ਮਾਹਰ ਖਾਸ ਉਦੇਸ਼ਾਂ ਲਈ ਪ੍ਰਾਪਤ ਡੇਟਾ ਵੀ ਪ੍ਰਦਾਨ ਕਰਦੇ ਹਨ।
ਸਿਖਲਾਈ ਡੇਟਾ ਵਿੱਚ ਨੈਤਿਕ ਵਿਚਾਰਾਂ 'ਤੇ ਜ਼ੋਰ ਦਿੱਤਾ ਗਿਆ
AI ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਤਰੱਕੀ ਦੇ ਨਾਲ, ਕਈ ਨੈਤਿਕ ਮੁੱਦੇ ਪੈਦਾ ਹੋਏ ਹਨ, ਖਾਸ ਤੌਰ 'ਤੇ ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ। ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ ਕੁਝ ਨੈਤਿਕ ਵਿਚਾਰਾਂ ਵਿੱਚ ਸੂਚਿਤ ਸਹਿਮਤੀ, ਪਾਰਦਰਸ਼ਤਾ, ਪੱਖਪਾਤ ਅਤੇ ਡੇਟਾ ਗੋਪਨੀਯਤਾ ਸ਼ਾਮਲ ਹਨ।ਕਿਉਂਕਿ ਡੇਟਾ ਵਿੱਚ ਹੁਣ ਚਿਹਰੇ ਦੀਆਂ ਤਸਵੀਰਾਂ, ਫਿੰਗਰਪ੍ਰਿੰਟਸ, ਵੌਇਸ ਰਿਕਾਰਡਿੰਗਾਂ, ਅਤੇ ਹੋਰ ਨਾਜ਼ੁਕ ਬਾਇਓਮੀਟ੍ਰਿਕ ਡੇਟਾ ਤੱਕ ਸਭ ਕੁਝ ਸ਼ਾਮਲ ਹੈ, ਇਸ ਲਈ ਮਹਿੰਗੇ ਮੁਕੱਦਮਿਆਂ ਅਤੇ ਵੱਕਾਰ ਨੂੰ ਨੁਕਸਾਨ ਤੋਂ ਬਚਣ ਲਈ ਕਾਨੂੰਨੀ ਅਤੇ ਨੈਤਿਕ ਅਭਿਆਸਾਂ ਦੀ ਪਾਲਣਾ ਨੂੰ ਯਕੀਨੀ ਬਣਾਉਣਾ ਬਹੁਤ ਮਹੱਤਵਪੂਰਨ ਹੋ ਰਿਹਾ ਹੈ।
ਭਵਿੱਖ ਵਿੱਚ ਹੋਰ ਵੀ ਬਿਹਤਰ ਗੁਣਵੱਤਾ ਅਤੇ ਵਿਭਿੰਨ ਸਿਖਲਾਈ ਡੇਟਾ ਦੀ ਸੰਭਾਵਨਾ
ਲਈ ਵੱਡੀ ਸੰਭਾਵਨਾ ਹੈ ਉੱਚ-ਗੁਣਵੱਤਾ ਅਤੇ ਵਿਭਿੰਨ ਸਿਖਲਾਈ ਡੇਟਾ ਭਵਿੱਖ ਵਿੱਚ. ਡੇਟਾ ਗੁਣਵੱਤਾ ਪ੍ਰਤੀ ਜਾਗਰੂਕਤਾ ਅਤੇ ਡੇਟਾ ਪ੍ਰਦਾਤਾਵਾਂ ਦੀ ਉਪਲਬਧਤਾ ਲਈ ਧੰਨਵਾਦ ਜੋ AI ਹੱਲਾਂ ਦੀ ਗੁਣਵੱਤਾ ਦੀਆਂ ਮੰਗਾਂ ਨੂੰ ਪੂਰਾ ਕਰਦੇ ਹਨ।
ਮੌਜੂਦਾ ਡਾਟਾ ਪ੍ਰਦਾਤਾ ਨੈਤਿਕ ਤੌਰ 'ਤੇ ਅਤੇ ਕਾਨੂੰਨੀ ਤੌਰ 'ਤੇ ਵਿਭਿੰਨ ਡੇਟਾਸੈਟਾਂ ਦੀ ਵੱਡੀ ਮਾਤਰਾ ਨੂੰ ਸਰੋਤ ਬਣਾਉਣ ਲਈ ਬੁਨਿਆਦੀ ਤਕਨੀਕਾਂ ਦੀ ਵਰਤੋਂ ਕਰਨ ਵਿੱਚ ਮਾਹਰ ਹਨ। ਉਹਨਾਂ ਕੋਲ ਵੱਖ-ਵੱਖ ML ਪ੍ਰੋਜੈਕਟਾਂ ਲਈ ਅਨੁਕੂਲਿਤ ਡੇਟਾ ਨੂੰ ਲੇਬਲ, ਐਨੋਟੇਟ ਅਤੇ ਪੇਸ਼ ਕਰਨ ਲਈ ਅੰਦਰੂਨੀ ਟੀਮਾਂ ਵੀ ਹਨ।
 AI ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਤਰੱਕੀ ਦੇ ਨਾਲ, ਕਈ ਨੈਤਿਕ ਮੁੱਦੇ ਪੈਦਾ ਹੋਏ ਹਨ, ਖਾਸ ਤੌਰ 'ਤੇ ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ। ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ ਕੁਝ ਨੈਤਿਕ ਵਿਚਾਰਾਂ ਵਿੱਚ ਸੂਚਿਤ ਸਹਿਮਤੀ, ਪਾਰਦਰਸ਼ਤਾ, ਪੱਖਪਾਤ ਅਤੇ ਡੇਟਾ ਗੋਪਨੀਯਤਾ ਸ਼ਾਮਲ ਹਨ।
AI ਵਿੱਚ ਤੇਜ਼ੀ ਨਾਲ ਤਰੱਕੀ ਦੇ ਨਾਲ, ਕਈ ਨੈਤਿਕ ਮੁੱਦੇ ਪੈਦਾ ਹੋਏ ਹਨ, ਖਾਸ ਤੌਰ 'ਤੇ ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ। ਸਿਖਲਾਈ ਡੇਟਾ ਇਕੱਤਰ ਕਰਨ ਵਿੱਚ ਕੁਝ ਨੈਤਿਕ ਵਿਚਾਰਾਂ ਵਿੱਚ ਸੂਚਿਤ ਸਹਿਮਤੀ, ਪਾਰਦਰਸ਼ਤਾ, ਪੱਖਪਾਤ ਅਤੇ ਡੇਟਾ ਗੋਪਨੀਯਤਾ ਸ਼ਾਮਲ ਹਨ।ਸਿੱਟਾ
ਡੇਟਾ ਅਤੇ ਗੁਣਵੱਤਾ ਦੀ ਤੀਬਰ ਸਮਝ ਦੇ ਨਾਲ ਭਰੋਸੇਯੋਗ ਵਿਕਰੇਤਾਵਾਂ ਨਾਲ ਭਾਈਵਾਲੀ ਕਰਨਾ ਮਹੱਤਵਪੂਰਨ ਹੈ ਉੱਚ-ਅੰਤ ਦੇ ਏਆਈ ਮਾਡਲਾਂ ਦਾ ਵਿਕਾਸ ਕਰੋ. ਸ਼ੈਪ ਇੱਕ ਪ੍ਰਮੁੱਖ ਐਨੋਟੇਸ਼ਨ ਕੰਪਨੀ ਹੈ ਜੋ ਤੁਹਾਡੀਆਂ AI ਪ੍ਰੋਜੈਕਟ ਲੋੜਾਂ ਅਤੇ ਟੀਚਿਆਂ ਨੂੰ ਪੂਰਾ ਕਰਨ ਵਾਲੇ ਅਨੁਕੂਲਿਤ ਡਾਟਾ ਹੱਲ ਪ੍ਰਦਾਨ ਕਰਨ ਵਿੱਚ ਮਾਹਰ ਹੈ। ਸਾਡੇ ਨਾਲ ਭਾਈਵਾਲੀ ਕਰੋ ਅਤੇ ਸਾਡੇ ਦੁਆਰਾ ਮੇਜ਼ 'ਤੇ ਲਿਆਏ ਜਾਣ ਵਾਲੀਆਂ ਯੋਗਤਾਵਾਂ, ਵਚਨਬੱਧਤਾ ਅਤੇ ਸਹਿਯੋਗ ਦੀ ਪੜਚੋਲ ਕਰੋ।


